The state of mainframe continuous delivery
What’s in this article
Mainframe continuous delivery overview
The literature
Issues with Mainframe-hosted solutions
Observations from the field
A glimpse into the future
Mainframe Continuous Delivery Overview
Continuous delivery is an approach to software delivery that seeks to break down the rigid series of phases through which software normally passes on the journey from a developer’s workstation to a production environment, so that value can be delivered to stakeholders with as little delay as possible. Wikipedia has a nice summary of continuous delivery that includes a sequence diagram showing a simplified continuous delivery process.
Practical continuous delivery for the mainframe environment has long been considered especially challenging. When we need to support applications that cross platforms, from mobile devices to web browsers to mid-tier systems to back-end systems, the challenges become enormous.
Here’s a simplified depiction of a generic continuous delivery process:
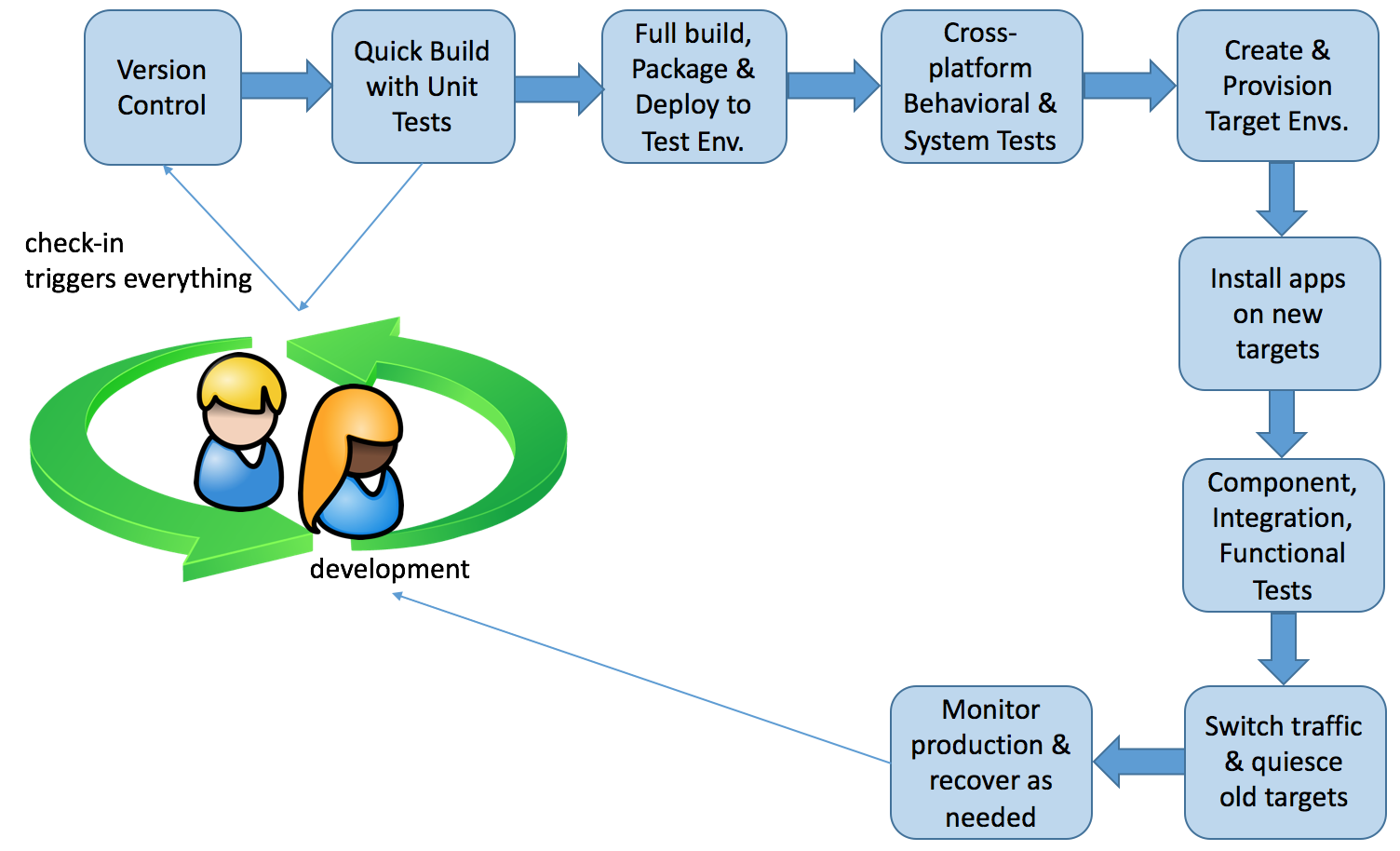
That picture will be familiar to developers who work on front-end stacks, as it has become relatively straightforward to set up a CD pipeline using (for instance) Github, Travis CI, and Heroku (or similar services).
When the “stack” is extended to the heterogeneous technologies commonly found in mainframe shops, here’s where we are, generally speaking:
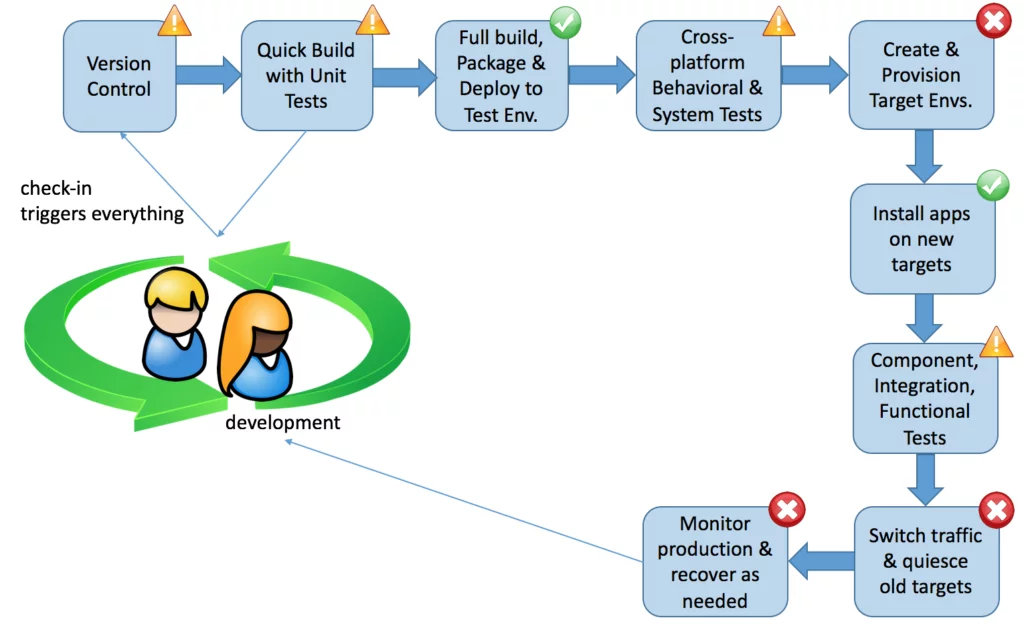
Many mainframe shops have mature tooling in place to support the migration of software from one environment to the next in their pipeline, as suggested by the green circles containing checkmarks.
The yellow “warning” triangles show steps in the CD pipeline where mainframe shops seem to have limited support as of this year. Notice that most of these steps are related to automated testing of one kind or another. On the whole, mainframe shops lack automated tests. Almost all testing is performed manually.
The first step in the diagram—version control—is shown with a yellow triangle. Most mainframe shops use version control for mainframe-resident code only. A separate version control system is used for all “distributed” code. The use of multiple version control systems adds a degree of complexity to the CD pipeline.
In addition, mainframe shops tend to use version control products that were originally designed to take snapshots of clean production releases, to be used for rollback after problematic installs. These products may or may not be well-suited to very short feedback cycles, such as the red-green-refactor cycle of test-driven development.
Mainframe shops are far behind in a few key areas of CD. They typically do not create, provision, and launch test environments and production environments on the fly, as part of an automated CD process. Instead, they create and configure static environments, and then migrate code through those environments. They don’t switch traffic from old to new targets because there is only one set of production targets.
The environments are configured manually, and the configurations are tweaked as needed to support new releases of applications. Test environments are rarely configured identically to production environments, and some shops have too few test environments for all development teams to share, causing still more delay in the delivery of value.
Database schema are typically managed in the same way as execution environments. They are created and modified manually and tweaked individually. Test databases are often defined differently than production ones, particularly with respect to things like triggers and referential integrity settings.
Test data management for all levels of automated tests is another problematic area. Many shops take snapshots of production data and scrub it for testing. This approach makes it difficult, if not impossible, to guarantee that a given test case will be identical every time it runs. The work of copying and scrubbing data is often handled by a dedicated test data management group or team, leading to cross-team dependencies, bottlenecks, and delays.
Finally, most mainframe shops have no automated production system monitoring in place. They deal with production issues reactively, after a human notices something is not working and reports it to a help desk, or after a system crashes or hangs. Should they need to roll back a deployment, the effort becomes an “all hands on deck” emergency that temporarily halts other value-add work in progress.
The literature
In reading published material on the subject of agile development / continuous deployment / DevOps for mainframe environments, I find two general types of information:
- Fluffy articles that summarize the concepts and admonish mainframe managers and operations to consider the importance of shortening lead times and tightening feedback loops in the delivery pipeline. None of these describes any working implementation currently in place anywhere.
- Articles crafted around specific commercial software products that support some subset of a continuous delivery pipeline for mainframe systems. None of these describes any working implementation currently in place anywhere.
As a starting point for learning about the challenges of continuous delivery in a mainframe environment, these types of articles are fine. There are a few shortcomings when it comes down to brass tacks.
Fluffy introductory articles
The limitations in the first type of article are easy to see. It’s important to understand the general concepts and the platform-specific issues at a high level, but after that you really need something more concrete.
Sometimes these very general articles remind me of the “How To Do It” sketch from Monty Python.
Alan: …here’s Jackie to tell you how to rid the world of all known diseases.Jackie: Well, first of all become a doctor and discover a marvelous cure for something, and then, when the medical world really starts to take notice of you, you can jolly well tell them what to do and make sure they get everything right so there’ll never be diseases any more.
Alan: Thanks Jackie, that was great. […] Now, how to play the flute. (picking up a flute) Well you blow in one end and move your fingers up and down the outside.
All well and good, except you can’t really take that advice forward. There just isn’t enough information. For instance, it makes a difference which end of the flute you blow in. Furthermore, it’s necessary to move your fingers up and down the outside in a specific way. These facts aren’t clear from the presentation. The details only get more and more technical from there.
Articles promoting commercial products
The second type of article provides information about concrete solutions. Companies have used these commercial solutions to make some progress toward continuous delivery. In some cases, the difference between the status quo ante and the degree of automation they’ve been able to achieve is quite dramatic.
Here are a few representative examples.
You may know the name Microfocus due to their excellent Cobol compiler. Microfocus has picked up Serena, a software company with several useful mainframe products, to bolster their ability to support mainframe customers.
It’s possible to combine some of these products to construct a practical continuous delivery pipeline for the mainframe platform:
- Serena ChangeMan ZMF with the optional Enterprise Release extension
- Serena Release Control
- Serena Deployment Automation Tool
- Microfocus Visual COBOL
Compuware offers a solution that, like Microfocus’ solution, comprises a combination of different products to fill different gaps in mainframe continuous delivery:
- Compuware ISPW
- Compuware Topaz Workbench
- XebiaLabs XL Release
IBM, the source of all things mainframe, can get you part of the way to a continuous delivery pipeline, as well. The “IBM Continuous Integration Solution for System Z” comprises several IBM products:
- Rational Team Concert
- Rational Quality Manager
- Rational Test Workbench
- Rational Integration Tester (formerly GreenHat)
- Rational Development and Test Environment (often called RD&T)
- IBM UrbanCode Deploy
Any of those offerings will get you more than half the pieces of a continuous delivery pipeline; different pieces in each case, but definitely more than half.
The software companies that focus on the mainframe platform are sincere about providing useful products and services to their customers. Even so, articles about products are sales pitches by definition, and a sales pitch naturally emphasizes the positives and glosses over any inconvenient details.
Issues with mainframe-hosted solutions
There are a few issues with solutions that run entirely, or almost entirely, on the mainframe.
Tight coupling of CD tooling with a single target platform
Ideally, a cross-platform CD pipeline ought to be managed independently of any of the production target platforms, build environments, or test environments. Only those components that absolutely must run directly on a target platform should be present on that platform.
For example, to deploy to a Unix or Linux platform it’s almost always possible to copy files to target directories. It’s rarely necessary to run an installer. Similarly, it’s a generally-accepted good practice to avoid running installers on any production Microsoft Windows instances. When Windows is used on production servers, it’s usually stripped of most of the software that comes bundled with it by default.
You don’t want to provide a means for the wrong people to install or build code on servers. At a minimum, code is built in a controlled environment and vetted before being promoted to any target production environment. Even better, the code and the environment that hosts it are both created as part of the build process; there’s no target environment waiting for things to be installed on it.
This means the CD tooling—or at least the orchestration piece—runs on its own platform, separate from any of the development, test, staging, production, or other platforms in the environment. It orchestrates other tools that may have to run on specific platforms, but the process-governing software itself doesn’t live on any platform that is also a deployment target.
An advantage is that the build and deploy process, as well as live production resiliency support, can build, configure, and launch any type of environment as a virtual machine without any need for a target instance to be pre-configured with parts of the CD pipeline installed. For mainframe environments, this approach is not as simple but can extend to launching CICS regions and configuring LPARs and zOS-hosted Linux VMs on the fly.
A further advantage of keeping the CD tooling separate from all production systems is that it’s possible to swap out any component or platform in the environment without breaking the CD pipeline. With the commercial solutions available, the CD tooling lives on one of the target deployment platforms (namely, the mainframe). Should the day come to phase out the mainframe, it would be necessary to replace the entire CD pipeline, a core piece of technical infrastructure. The enterprise may wish to keep that flexibility in reserve.
It isn’t always possible to deploy by copying binaries and configuration files to a target system. There may be various reasons for this. In the case of the mainframe, the main reason is that no off-platform compilers and linkers can prepare executable binaries you can just “drop in” and run.
Mainframe compatibility options in products like Microfocus COBOL and Gnu COBOL don’t produce zOS-ready load modules; they provide source-level compatibility, so you can transfer the source code back and forth without any modifications. A build of the mainframe components of an application has to run on-platform, so at some point in the build-and-deploy sequence the source code has to be copied to the mainframe to be compiled.
This means build tools like compilers and linkers must be installed on production mainframes. That isn’t a problem, as mainframe systems are designed to keep build tools separate from production areas. But the fact builds must run on-platform doesn’t mean the CD pipeline orchestration tooling itself has to run on-platform (except, maybe, for an agent that interacts with the orchestrator). For historical and cultural reasons, this concept can be difficult for mainframe specialists to accept.
Multiple version control systems
When you use a mainframe-based source code manager (Serena ChangeMan, CA-Endevor, etc.) for mainframe-hosted code, and some other version control system (Git, Subversion, etc.) for all the “distributed” source code, you have the problem of dual version control systems. Moving all the “distributed” code to the mainframe just for the purpose of version control surely makes no sense.
When your applications cut through multiple architectural layers, spanning mobile devices, web apps, Windows, Linux/Unix, and zOS, having dual version control systems significantly increases the likelihood of version conflicts and incompatible components being packaged together. Rollbacks of partially-completed deployments can be problematic, as well.
It’s preferable for all source code to be managed in the same version control sytem, and for that system to be independent of any of the target platforms in the environment. One of the key challenges in this approach is cultural, and not technical. Mainframe specialists are accustomed to having everything centralized on-platform. The idea of keeping source code off-platform may seem rather odd to them.
But there’s no reason why source code has to live on the same platform where executables will ultimately run, and there are plenty of advantages to keeping it separate. Advantages include:
- Ability to use off-platform development tools that offer much quicker turnaround of builds and unit tests than any on-platform configuration
- Ability to keep development and test relational databases absolutely synchronized with production schema by building from the same DDL on the fly (assuming DB2 on all platforms)
- Ability to keep application configuration files absolutely synchronized across all environments, as all environments use the same copy of configuration files checked out from the same version control system
- other advantages along the same general lines
If you assume source code management systems are strictly for programming language source code, the above list may strike you as surprising. Actually, any and all types of “source” (in a general sense) ought to be versioned and managed together. This includes, for all target platforms that host components of a cross-platform application:
- source code
- application configuration files
- system-related configuration settings (e.g., batch job scheduler settings, preconfigured CICS CSD files, etc.)
- database schema definitions (e.g., DDL for relational DBs)
- automated checks/tests at all levels of abstraction
- documentation (for all audiences)
- scripts for configuring/provisioning servers
- JCL for creating application files (VSAM, etc.)
- JCL for starting mainframe subsystems (e.g., CICS)
- scripts and/or JCL for application administration (backup/restore, etc.)
- scripts and/or JCL for running the application
- anything else related to a version of the application
All these items can be managed using any version control system hosted on any platform, regardless of what sort of target system they may be copied to, or compiled for.
Limited support for continuous integration
In typical “agile”-style software development work, developers depend on short feedback cycles to help them minimize the need for formality to keep the work moving forward as well as to help ensure high quality and good alignment with stakeholder needs.
Mainframe-based development tools tend to induce delay into the developers’ feedback cycle. It’s more difficult to identify and manage dependencies, more time-consuming to build the application, and often more labor-intensive to prepare test data than in the “distributed” world of Java, Ruby, Python, and C#. For historical reasons, this isn’t necessarily obvious to mainframe specialists, as they haven’t seen that sort of work flow before.
In traditional mainframe environments, it’s common for developers to keep code checked out for weeks at a time and to attempt a build only when they are nearly ready to hand off the work to a separate QA group for testing. They are also accustomed to “merge hell.” Many mainframe developers simply assume “merge hell” is part of the job; the nature of the beast, if you will. Given that frame of reference, tooling that enables developers to integrate changes and run a build once a day seems almost magically powerful.
Mainframe-based CI/CD tools do enable developers to build at least once per day. But that’s actually too slow to get the full benefit of short feedback cycles. It’s preferable to be able to turn around a single red-green-refactor TDD cycle in five or ten minutes, if not less, with your changes integrated into the code base every time. That level of turnaround is all but unthinkable to many mainframe specialists.
Mainframe-based version control systems weren’t designed with that sort of work flow in mind. They were spawned in an era when version control was used to take a snapshot of a clean production release, in case there was a need to roll back to a known working version of an application in future. These tools weren’t originally designed for incremental, nearly continuous integration of very small code changes. Despite recent improvements that have inched the products closer to that goal, it’s necessary to manage version control off-platform in order to achieve the feedback cycle times and continuous integration contemporary developers want.
Limited support for automated unit testing
Contemporary development methods generally emphasize test automation at multiple levels of abstraction, and frequent small-scale testing throughout development. Some methods call for executable test cases to be written before writing the production code that makes the tests pass.
These approaches to development require tooling that enables very small subsets of the code to be tested (as small as a single path through a single method in a Java class), and for selected subsets of test cases to be executed on demand, as well as automatically as part of the continuous integration flow.
Mainframe-based tooling to support fine-grained automated checks/tests is very limited. The best example is IBM’s zUnit testing framework, supporting Cobol and PL/I development as part of the Rational suite. But even this product can’t support unit test cases at a fine level of granularity. The smallest “unit” of code it supports is an entire load module.
Some tools are beginning to appear that improve on this, such as the open source cobol-unit-test project for Cobol, and t-rexx for test-driving Rexx scripts, but no such tool is very mature at this time. The cobol-unit-test project can support fine-grained unit testing and test-driving of Cobol code off-platform using a compiler like Microfocus or Gnu COBOL, on a developer’s Windows, OSX, or Linux machine or in a shared development environment. No mainframe-based tools can support this.
Dependencies outside the developer’s control
A constant headache in mainframe development is the fact it’s difficult to execute a program without access to files, databases, and subroutine libraries the developer doesn’t control. Even the simplest, smallest-scale automated test depends on the availability and proper configuration of a test environment, and these are typically managed by a different group than the development teams.
Every developer doesn’t necessarily have their own dedicated test files, databases, CICS regions, or LPARs. In many organizations, developers don’t even have the administrative privileges necessary to start up a CICS region for development or testing, or to modify CICS tables in a development region to support their own needs; a big step backward as compared with the 1980s. Developers have to take turns, sometimes waiting days or weeks to gain access to a needed resource.
Mainframe-based and server-based CD tooling addresses this issue in a hit-or-miss fashion, but none provides robust stubbing and mocking support for languages like Cobol and PL/I.
Some suites of tools include service virtualization products that can mitigate some of the dependencies. Service virtualization products other than those listed above may be used in conjunction, as well (e.g., Parasoft, HP).
The ability to run automated checks for CICS applications at finer granularity than the full application is very limited short of adding test-aware code to the CICS environment. IBM’s Rational Suite probably does the best job of emulating CICS resources off-platform, but at the cost of requiring multiple servers to be configured. These solutions provide only a partial answer to the problem.
Disconnected and remote development is difficult
One factor that slows developers down is the necessity to connect to various external systems. Even with development tools that run on Microsoft Windows, OSX, or Linux, it’s necessary for developers to connect to a live mainframe system to do much of anything.
To address these issues, IBM’s Rational suite enables developers to work on a Windows workstation. This provides a much richer development environment than the traditional mainframe-based development tools. But developers can’t work entirely isolated from the network. They need an RD&T server and, possibly, a Green Hat server to give them VSAM and CICS emulation and service virtualization for integration and functional testing.
Each of these connections is a potential failure point. One or more servers may be unavailable at a given time. Furthermore, the virtual services or emulated facilties may be configured inappropriately for a developer’s needs.
Keep in mind the very short feedback cycles that characterize contemporary development methods. Developers typically spend as much as 90% of their time at the “unit” level; writing and executing unit checks and building or modifying production code incrementally, to make those checks pass. They spend proportionally less time writing and executing checks at the integration, functional, behavioral, and system levels.
Therefore, an environment that enables developers to work without a connection to the mainframe or to mainframe emulation servers can enable them to work in very quick cycles most of the time.
In addition, the level of granularity provided by zUnit isn’t sufficient to support very short cycles such as Ruby, Python, C#, or Java developers can experience with their usual tool stacks.
In practical terms, to get to the same work flow for Cobol means doing most of the unit-level development on an isolated Windows, OSX, or Linux instance with an independent Cobol compiler such as Microfocus or Gnu COBOL, and a unit testing tool that can isolate individual Cobol paragraphs. Anything short of that offers only a partial path toward continuous delivery.
Observations from the field
Version control
Possibly the most basic element in a continuous delivery pipeline is a version control system for source code, configuration files, scripts, documentation, and whatever else goes into the definition of a working application. Many mainframe shops use a mainframe-based version control system such as CA-Endevor or Serena ChangeMan. Many others have no version control system in place.
The idea of separating source repositories from execution target platforms has not penetrated. In principle there is no barrier to keeping source code and configuration files (and similar artifacts) off-platform so that development and unit-level testing can be done without the need to connect to the mainframe or to additional servers. Yet, it seems most mainframe specialists either don’t think of doing this, or don’t see value in doing it.
Automated testing (checking)
Most mainframe shops have little to no automated testing (or checking or validation, as you prefer). Manual methods are prevalent, and often testing is the purview of a separate group from software development. Almost as if they were trying to maximize delay and miscommunication, some shops use offshore testing teams located as many timezones away as the shape of the Earth allows.
So, what’s all this about “levels” of automated testing? Here’s a depiction of the so-called test automation pyramid. You can find many variations of this diagram online, some simpler and some more complicated than this one.
Automated testing (checking)
Most mainframe shops have little to no automated testing (or checking or validation, as you prefer). Manual methods are prevalent, and often testing is the purview of a separate group from software development. Almost as if they were trying to maximize delay and miscommunication, some shops use offshore testing teams located as many timezones away as the shape of the Earth allows.
So, what’s all this about “levels” of automated testing? Here’s a depiction of the so-called test automation pyramid. You can find many variations of this diagram online, some simpler and some more complicated than this one.
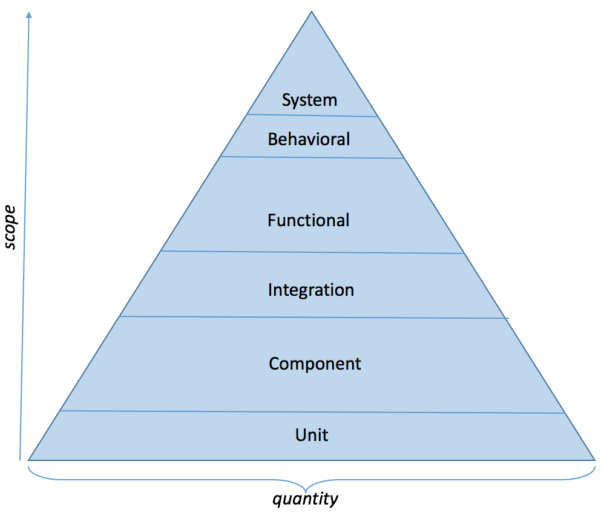
This is all pretty normal for applications written in Java, C#, Python, Ruby, C/C++ and other such languages. It’s very unusual to find these different levels of test automation in a mainframe shop. Yet, it’s feasible to support several of these levels without much additional effort:
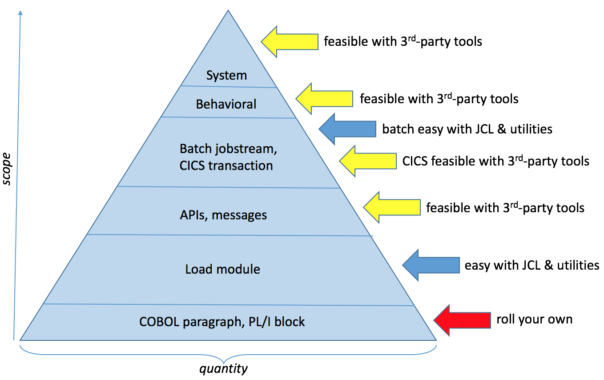
Automation is quite feasible and relatively simple for higher-level functional checking and verifying system qualities (a.k.a. “non-functional” requirements). The IBM Rational suite includes service virtualization (and so do other vendors), making it practical to craft properly-isolated automated checks at the functional and integration levels. Even so, relatively few mainframe shops have any test automation in place at any level. Some mainframe specialists are surprised to learn there is such a thing as different “levels” of automated testing; they can conceive only of end-to-end tests with all interfaces live. This is a historical and cultural issue, and not a technical one.
At the “unit” level, the situation is reversed. The spirit is willing but the tooling is lacking. IBM offers zUnit, which can support test automation for individual load modules. To get down to a suitable level of granularity for unit testing and TDD, there are no well-supported, commercial tools. To be clear: A unit test case exercises a single path through a single Cobol paragraph or PL/I block. The “unit” in zUnit is the load module; I would call that a component test rather than a unit test. There are a few Open Source unit testing solutions to support Cobol, but nothing for PL/I. And this is where developers spend 90% of their time. It is an area that would benefit from further tool development.
Test data management
When you see a presentation about continuous delivery at a conference, the speaker will display illustrations of their planned transition to full automation. No one (that I know of) has fully implemented CD in a mainframe environment. The presentations typically show test data management as just one more box among many in a diagram, the same size as all the other boxes. The speaker says they haven’t gotten to that point in their program just yet, but they’ll address test data management sometime in the next few months. They sound happy and confident. This tells me they’re speeding toward a brick wall, and they aren’t aware of it.
Test data management may be the single largest challenge in implementing a CD pipeline for a heterogeneous environment that includes mainframe systems. People often underestimate it. They may visualize something akin to an ActiveRecord migration for a Ruby application. How hard could that be?
Mainframe applications typically use more than one access method. Mainframe access methods are roughly equivalent to filesystems on other platforms. It’s common for a mainframe application to manipulate files using VSAM KSDS, VSAM ESDS, and QSAM access methods, and possibly others. To support automated test data management for these would be approximately as difficult as manipulating NTFS, EXT4, and HFS+ filesystems from a single shell script on a single platform. That’s certainly do-able, but it’s only the beginning of the complexity of mainframe data access.
A mature mainframe application that began life 25 years ago or more will access multiple databases, starting with the one that was new technology at the time the application was originally written, and progressing through the history of database management systems since that time. They are not all SQL-enabled, and those that are SQL-enabled generally use their own dialect of SQL.
In addition, mainframe applications often comprise a combination of home-grown code, third-party software products (including data warehouse products, business rules engines, and ETL products—products that have their own data stores), and externally-hosted third-party services. Development teams (and the test data management scripts they write) may not have direct access to all the data stores that have to be populated to support automated tests. There may be no suitable API for externally-hosted services. The company’s own security department may not allow popular testing services like Sauce Labs to access applications running on internal test environments, and may not allow test data to go outside the perimeter because sensitive information could be gleaned from the structure of the test data, even if it didn’t contain actual production values.
Creating environments on the fly
Virtualization and cloud services are making it more and more practical to spin up virtual machines on demand. People use these services for everything from small teams maintaining Open Source projects to resilient solution architectures supporting large-scale production operations. A current buzzword making the rounds is hyperconvergence, which groups a lot of these ideas and capabilities together.
But there are no cloud services for mainframes. The alternative is to handle on-demand creation of environments in-house. Contemporary models of mainframe hardware are capable of spinning up environments on demand. It’s not the way things are usually done, but that’s a question of culture and history and is not a technical barrier to CD.
IBM’s z/VM can manage multiple operating systems on a single System z machine, including z/OS. With PR/SM (Processor Resource/System Manager) installed, z/OS logical partitions (LPARs) are supported. Typically, mainframe shops define a fixed set of LPARs and allocate development, test, and production workloads across them. The main reason it’s done that way is that creating an LPAR is a multi-step, complicated process. People prefer not to have to do it frequently. (All the more reason to automate it, if you ask me.)
A second reason, in some cases, is that the organization hasn’t updated its operating procedures since the 1980s. They have a machine that is significantly more powerful than older mainframes, and they continue to operate it as if it were severely underpowered. I might observe this happens because year after year people say “the mainframe is dying, we’ll replace it by this time next year,” so they figure it isn’t worth an investment greater than the minimum necessary to keep the lights on.
Yet, the mainframe didn’t die. It evolved.
Production system monitoring
A number of third-party tools (that is, non-IBM tools) can monitor production environments on mainframe systems. Most shops don’t use them, but they are available. A relatively easy step in the direction of CD is to install appropriate system monitoring tools.
Generally, such tools are meant for performance monitoring. They help people tune their mainframe systems. They aren’t really meant to support dynamic reconfiguration of applications on the fly.
Ideally, we want these tools to be able to do more than just notify someone when they detect a problematic condition. The same sort of resiliency as reactive architectures provide would be most welcome for mainframe systems, as well. This may be a future development.
A glimpse into the future?
I saw a very interesting demo machine a couple of years ago. An IBMer brought it to a demo of the Rational suite for a client. It was an Apple MacBook Pro with a full-blown instance of zOS installed. It was a single-user mainframe on a laptop. It was not, and still is not, a generally-available commercial product.
That sort of thing will only become more practical and less costly as technology continues to advance. One can imagine a shop in which each developer has their own personal zOS system. Maybe they’ll be able to run zOS instances as VMs under VirtualBox or VMware. Imagine the flexibility and smoothness of the early stages in a development work flow! Quite a far cry from two thousand developers having to take turns sharing a single, statically-defined test environment for all in-flight projects.
The pieces of the mainframe CD puzzle are falling into place by ones and twos.
Comments (8)
donbul91
I don’t agree: http://www.fosspatents.com/2010/08/two-faces-of-mainframe-different.html
Sincerely, Donnetta
Nice article, but I don’t see the connection with my post as the topics are completely different. It’s unclear what you disagree with.
Steve Pettit
Hi Dave – great article, and well aligned with my experiences (I work in a mainframe agile team, which is currently a long way from be able to build, test and deploy within 2 week sprint windows). We have IBM tools on the way, which as you suggest may help in some areas – but I’d be keen to get your estimate of when the tools will be available and mature enough to allow full continuous delivery for mainframe applications? When will we be developing on our laptops totally disconnected from the mainframe, and using the same tools as our Java buddies to then move and automatically test the results? It would be great if you thought it would all be happening in 2017, but I’m not holding my breath…
Hi Steve,
I don’t speak for IBM or any other tooling company, and I can’t guess when a completely seamless environment might be available for mainframe development that’s as easy to set up as a mainstream Java, Ruby, Python, or .NET environment.
I have some awareness of the approach some of the companies are taking, and they aren’t focusing on detaching the development environment from the mainframe system. They are finding ways to streamline development activities to reduce the delay inherent in using on-platform tools like OEDIT, by providing more-contemporary style IDEs with familiar features like code completion. You have to be connected to the enterprise network to do anything useful with these tools, but maybe that’s okay in the context of IT work in large organizations. The key thing is to streamline the work flow so that we can get things done in short increments.
Personally, I like the idea of consolidating all source into a single version control system. As most organizations today have a heterogeneous infrastructure, and it’s inconvenient to pull source from the mainframe to run on dozens or hundreds of Linux and Windows VMs and assorted one-off platforms, it makes sense for that version control system to be hosted off-platform. I’m thinking of something like Git, of course. Code can be transferred to the mainframe for compilation as part of the delivery pipeline. But tool vendors aren’t approaching the problem from this direction.
I’ve observed an odd phenomenon in our industry. We might call it a “tool fetish.” For some reason, perfectly well-qualified programmers wait for “someone” to provide them with a “tool” to do whatever they need to do. When it comes to things like BDD, TDD, and automated deployment, people who work on the mainframe platform don’t have a large array of tools to choose from, as compared with (for instance) web developers. But they can write their own tools. It would take far less time than waiting for the big software companies to make tools for them.
Here’s a set-up I’ve used for real work: (1) Linux VM, (2) Gnu COBOL, (3) Sublime Text 3, (4) FTP, (5) a little Bash, (6), a little Ruby, (7) a hand-rolled unit testing framework for COBOL. For testing batch job steps, add BerkeleyDB and a little more Ruby and you can make a reasonable facsimile of VSAM files suitable for simple functional testing appropriate for CI.
Yes, it takes some time and effort, but not as much time as waiting for a magic tool to appear. When the magic tool finally does appear, you can transfer your test cases from the hand-rolled tooling bit by bit and then discard the hand-rolled code. The point is, we aren’t prisoners. We don’t have to wait for the big companies to give us a finished product before we can even begin to work.
Regarding that amazing mainframe-on-a-laptop based on a MacBook Pro, there are a number of those units floating around but they aren’t available to the general public as far as I know. People who work at mainframe-focused software firms are using them on an experimental basis. No idea whether or when they might become generally available, or what they would cost.
All I can advise is this: If you need to do something, then find a way to do it. It’s just code, after all.
Cheers!
Steve Pettit
Thanks Dave – we’re actually building a test tool right now to automate one area, and looking at scripting to automate other tasks that are currently manual. The challenge is to find the time to progress these initiatives in amongst delivering the change that’s asked of us – so it takes time. Thanks again for your response, much appreciated.
Yes, finding time to do these things in the midst of regular work is always a challenge. One approach that may be helpful is to do it incrementally. That’s not always feasible, but sometimes you can bake in the time to build test scripts/programs/JCL/whatever into the User Story size. You don’t need to ask anyone’s permission to do this. It’s just part of the way you’ve chosen to complete the Story. Of course, when you have to build a significant amount of tooling, that approach won’t work.
Keep up the good work!
Bob Wilmes
This is an excellent article on a timely subject with no easy answers as it addresses the modernization of legacy code bases in the Z/OS environment. First of all, the article doesn’t mention anything regarding Unix System Services on z/OS, nor the number of free z/OS tools such as Git for z/OS and modern languages like R or Python available from Rocket Software. Second – the article has been updated regarding the appearance of Docker containers for z/OS on the IBM z14 mainframes which will certainly have an impact on agile development processes. Finally the article doesn’t mention the impact of Conway’s Law – that organizations are structured to the way work is accomplished in a z?OS environment. Hence CICS specialists are rarely the same people as z/OS specialists or IMS specialists, etc. COBOL programs written for specific releases of CICS Transaction Server also include layered application frameworks such as Hogan Banking which are themselves are as complex as operating systems.
My personal opinion is it is a naïve quest to separate an agile methodology from specific tool chains never designed for DevOps. Similar issues exist in the embedded programming marketplace with tool chains for ARM processors like Keil.
What I really missed in this article is a prescriptive solution for z/OS, for example, why someone would choose a text based source code management system like Git, over one that can handle audit trails and binary objects like Subversion. There are many mock up utilities like JUnit available for unit testing, even on the mainframe. As the author notes, the paucity of unit test frameworks for CICS COBOL doesn’t lend itself to CICS DevOps easily. It is possible to build some of these effectively using external platforms like Sonar Cube or HP Quality Center.
Dave -please expand and update this article. Great job!
larry england
The ‘full blown instance of z/OS running on a laptop’ is indeed available now as a product called zD&T (https://developer.ibm.com/mainframe/products/z-systems-development-test-environment/). Combining this with the unique cloud capabilities offered by Skytap.com, one can create an instance of the zD&T in the cloud (complete with DB2, VSAM data bases, PDS’s, CICS Regions etc), create a template from it using the Skytap native capabilities, and either via a web interface, or via scripted RESTful web services, create a running instance of a z/OS environment within minutes. One environment could be a ‘build server’ in which the real z/OS COBOL and/or PL/I compilers are available. Other environments can be started from the template for testing purposes (at various levels as you’ve described). Caveats: Since the z/OS environment (zD&T) is really an emulator, you cannot conduct performance testing — nor can you use one of these environments to run production code (license restrictions).
Bottom line, you can have ephemeral z/OS environments instantiated in a self-serve manner (or scripted), used for purpose, and then deleted once you are done with your task.