Which tools should you choose for UI and API testing?
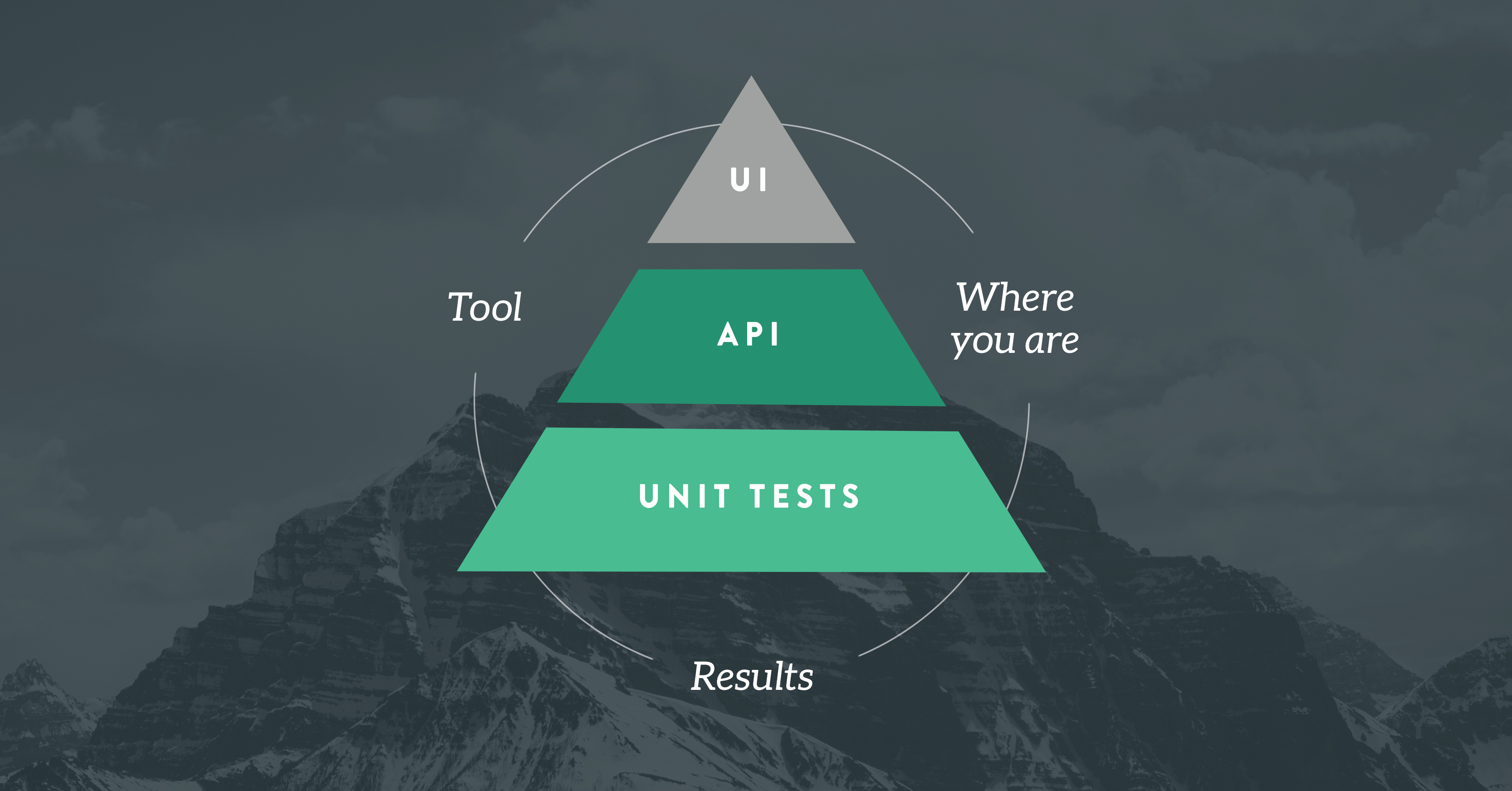


By now, everyone has seen the “test automation pyramid” a thousand times or more. You can find countless illustrations of it online.
The base comprises a large number of automated checks of small scope. As we ascend, we check progressively larger chunks of code and we need relatively fewer cases than in the layer below.
The core idea is to get as much value from each check as we can with the least investment of time, money, and effort. Checks higher on the pyramid involve more resources and more interfaces than checks lower on the pyramid, so they are inherently more expensive. The more we can learn through less-expensive, lower-level checks, the better off we are.
When working with organizations that are only now beginning to fill the gaps in test automation, there’s always a lot of discussion about tools. There’s a tendency for people to want to avoid throwing numerous different tools into the mix, as that will make the environment harder to understand and maintain and increase the chances that Thing One won’t work properly alongside Thing Two.
That’s sound thinking, but it can be taken beyond the point of diminishing returns. In the context of automated checking, different tools may provide the best results depending on where we are on the pyramid.
Microtests
All the illustrations of the pyramid that I’ve seen so far show “unit tests” at the base. With contemporary development practices, the base is really even smaller than that; it’s microtests.
Microtests are written and maintained by programmers. They are the basis of test-driven development (TDD). A single example will exercise just one logical path through just one very small-scale unit of code. In order to do this, the example has to be written in the same language as the code under test. (It’s possible someone has created a low-level testing tool that contradicts that statement, but as a general rule it’s the reality on the ground.)
So, if you had some C# code like this:
using System;
namespace Prime.Services
{
public class PrimeService
{
public bool IsPrime(int candidate)
{
if (candidate < 2 || candidate % 2 == 0)
{
return false;
}
int boundary = (int)Math.Floor(Math.Sqrt(candidate));
for (int i = 3 ; i <= boundary ; i += 2)
{
if (candidate % i == 0)
{
return false;
}
}
return true;
}
}
}
then you would want to have a microtest for each logical path through the method, IsPrime. Maybe something like this:
using Microsoft.VisualStudio.TestTools.UnitTesting;
using Prime.Services;
namespace Prime.UnitTests.Services
{
[TestClass]
public class PrimeService_IsPrimeShould
{
private readonly PrimeService _primeService;
public PrimeService_IsPrimeShould()
{
_primeService = new PrimeService();
}
[DataTestMethod]
[DataRow(-1)]
[DataRow(0)]
[DataRow(1)]
public void ValuesLessThan_2_AreNotPrime(int value)
{
var result = _primeService.IsPrime(value);
Assert.IsFalse(result, $"{value} is not prime");
}
[DataTestMethod]
[DataRow(4)]
[DataRow(80)]
[DataRow(2000)]
public void ValuesDivisbleBy_2_AreNotPrime(int value)
{
var result = _primeService.IsPrime(value);
Assert.IsFalse(result, $"{value} is not prime");
}
[TestMethod]
public void Value_81_IsNotPrime()
{
Assert.IsFalse(_primeService.IsPrime(81), "81 is not prime");
}
[TestMethod]
public void Value_13_IsPrime()
{
Assert.IsTrue(_primeService.IsPrime(13), "13 is prime");
}
}
}
Similarly, if you had some COBOL code to determine the next invoice date, like this:
2000-NEXT-INVOICE-DATE.
EVALUATE TRUE
WHEN FEBRUARY
PERFORM 2100-HANDLE-FEBRUARY
WHEN 30-DAY-MONTH
MOVE 30 TO WS-CURRENT-DAY
WHEN OTHER
MOVE 31 TO WS-CURRENT-DAY
END-EVALUATE
MOVE WS-CURRENT-DATE TO WS-NEXT-INVOICE-DATE
.
then you would want one microtest for each logical path through the paragraph, 2000-NEXT-INVOICE-DATE. Maybe something like this:
TESTCASE "IT DETERMINES THE NEXT INVOICE DATE IN A 30-DAY MONTH"
MOVE "20150405" TO WS-CURRENT-DATE
PERFORM 2000-NEXT-INVOICE-DATE
EXPECT WS-NEXT-INVOICE-DATE TO BE "20150430"
TESTCASE "IT DETERMINES THE NEXT INVOICE DATE IN A 31-DAY MONTH"
MOVE "20150705" TO WS-CURRENT-DATE
PERFORM 2000-NEXT-INVOICE-DATE
EXPECT WS-NEXT-INVOICE-DATE TO BE "20150731"
TESTCASE "IT DETERMINES THE NEXT INVOICE DATE IN FEB, NON LEAP"
MOVE "20150205" TO WS-CURRENT-DATE
PERFORM 2000-NEXT-INVOICE-DATE
EXPECT WS-NEXT-INVOICE-DATE TO BE "20150228"
TESTCASE "IT DETERMINES THE NEXT INVOICE DATE IN FEB, LEAP"
MOVE "20160205" TO WS-CURRENT-DATE
PERFORM 2000-NEXT-INVOICE-DATE
EXPECT WS-NEXT-INVOICE-DATE TO BE "20160229"
A point to take from these examples is that when we need to isolate a small section of a unit of code, exercise just that section, and make assertions about the behavior that section exhibits in isolation from the rest of the code, then we have to write our automated checks in the same language as the code under test. A Python or Ruby program can’t directly look at the result of a C# method or a COBOL paragraph. A testing tool in Python or Ruby would have to check the validity of the method or paragraph indirectly, as part of a larger-scope check. That way lies madness.
That’s the basis of the reasoning that test cases should be written in the same language as the code under test. The question is: Does the same reasoning apply at higher levels of the test automation pyramid?
The Nature of UI and API Checks
It’s commonplace for people to say things like, “We’re a Java shop, so we need to use Java-based testing tools even for high-level checks against APIs and UIs.” It makes sense to write microtests in Java for applications written in Java. But is that the right choice for writing automated checks against a web page, a mobile device, a CICS screen, a command-line interface, a SOAP API, or a RESTful API?
What about organizations in which applications are written in more than one language? What we often see in those cases is that the technical staff divide into “camps” and endlessly debate the choice of tools. “Our team writes microservices in Java, so we need to use [for instance] RestAssured for API checks,” versus, “Our team writes microservices in C#, so we need to use [for instance] SpecFlow for API checks.” Now you have to maintain two code bases of automated checks.
The thing is, API checks are not the same thing as microtests. They don’t assert the results of individual methods in the application. They assert the results of service invocations, usually over HTTP. When you invoke a service over HTTP, like when you do a Google search, do you need to know what language the service was written in?
Similarly, checks against mobile apps, web pages, CICS screens, and command-line interfaces don’t know or care about the programming languages used in the applications behind the APIs. There’s no technical reason that such checks have to be written in the same language as the code under test.
In fact, forcing the issue and requiring all testing tools to be in the same language as applications can easily cause more harm than good.
Knowledge Gaps (and Fear of Same)
The second most common reason people want to stick to a single language for all automated checks is that the technical staff may not be familiar with other languages. “Our developers know Java very well, but they don’t know Ruby. Therefore, they must use [for instance] Cucumber-JVM rather than Cucumber.”
The people who raise this concern are usually in one of two groups: (a) non-technical managers who (apparently) assume the human brain has the capacity to learn exactly one programming language, and (b) programmers who are (unfortunately) close to the wrong end of the bell curve (although awesome.)
There are two fundamental logical errors behind this concern.
First, the technical staff already knows and uses multiple programming languages and related tools, such as scripting languages, markup languages, job control languages, and tools for configuring, integrating, building, running, packaging, and deploying their code. Even if the application as such is written in just one language, the technical staff has to use a range of different tools to work with the code base.
Second, competent programmers enjoy learning new languages. They entered the field in the first place because they enjoy solving problems and creating software. The programmers will be happy to have the opportunity to learn (a) testing skills and (b) new languages and tools.
Fit for Purpose
Ideally, we’d like to use whatever automated checking tools make sense for each category of checking we need to perform, and for each layer of the test automation pyramid. We’ve already seen the necessity to write microtests in the same language as the code under test.
For UI and API checks, we want to choose tools that give us good functionality and flexibility for checking UIs and APIs; not necessarily for asserting the results of individual Java or C# methods and so forth. It’s a different use case.
Testing Tools Add Value but Aren’t Magic
There’s no magic involved in accessing a service over HTTP. To illustrate, let’s access a service using *nix command-line programs that are commonly installed. We don’t want to imply that this is a great way to create a large suite of executable checks that will be maintained for years. The purpose is only to show that there’s no need to write API checks in the same programming language that was used to write the system under test.
As of the date of publication, there’s a sample microservice on Heroku we can use for this demonstration. It’s called rpn-service, and it is a Reverse Polish Notation (RPN) calculator. Using curl to invoke the service and jq to see what it returns, we get the following:
curl -s 'http://rpn-service.herokuapp.com' | jq '.'
And the result:
{
"usage": [
{
"path": "/calc/*",
"description": "pass values in postfix order, like this: /calc/6/4/5/+/*. To avoid conflicts with URL strings, use \"d\" instead of \"/\\\" for division."
}
]
}So, when we invoke the service with no arguments it returns usage help. We can see the JSON response document contains a key “usage” that has an array of entries with one entry. Let’s check to ensure the “description” entry contains the text, “pass values in postfix order”:
curl -s 'http://rpn-service.herokuapp.com' | jq '.usage[0].description' | perl -wnE'say /pass values in postfix order/g'
That gets us:
pass values in postfix order
Wrapping that in a bash script, we can check to see that the regex finds a match and call that a ‘pass’.
#!/bin/bash
if [[ $(curl -s 'http://rpn-service.herokuapp.com' | jq '.usage[0].description' | perl -wnE'say /pass values in postfix order/g') ]]; then
echo 'pass'
else
echo 'fail'
fi
You can see that we don’t need any special testing tools to check the result of an API call, and that we don’t need to write our executable checks in the same programming language as the system under test.
Good testing tools add value beyond that, of course. They help us with organizing test cases, hiding ugly details under the covers, and running subsets of test suites based on criteria that we define, such as long- vs. short-running cases or cases pertaining to particular application features. They’re also generally easier to live with than command-line programs and shell scripts.
The point is the idea that tests and application code must be written in the same programming language is a myth, or perhaps merely a fear.
Considerations for Choosing API Testing Tools
Different organizations have different needs and often have unique technical environments. The following considerations are often relevant in larger corporate IT organizations:
- Services may be hosted in-house or in the cloud, and may reside on a range of different platforms. These often include some flavor of Linux (usually Red Hat Enterprise or Suse), some flavor of Unix (usually IBM AIX or HP-UX, and sometimes Solaris even though it is being phased out), an enterprise platform that exposes a Unix-like shell (HP NonStop/Tandem, IBM zOS), and/or some flavor of Microsoft Windows.
- The majority of software developers working in large corporate IT shops use Microsoft Windows development systems. Some use Apple OSX or some flavor of Linux. Those who do mobile development as well as API development most likely use Apple OSX.
- API test suites may be quite large, often containing thousands of cases. At various points in the development cycle, subsets of these cases must be executed, but not the entire suite. Different criteria for grouping and selecting test cases may apply.
- API checks must be executable in an interactive mode as well as being scriptable for inclusion in a CI build.
- Services are most often invoked using RESTful or SOAP-based standards. In older IT shops, there may be service-like interfaces exposed internally, based on older interfaces that may be non-standard.
- One function of automated test suites is to provide documentation of the system under test. In contrast with conventional documentation, executable documentation that is maintained in sync with production code can never be out of date or inaccurate.
- Different kinds of testing provide different kinds of value. Both example-based and property-based testing are generally advisable.
Considerations 1 and 2 suggest we want tools that are platform-agnostic. In a pure Microsoft shop, VSTS and SpecFlow and friends might be fine. Most corporate environments are technically heterogeneous. Tools built on cross-platform lanaguages like Java (e.g., RestAssured, JBehave, Cucumber-JVM), Ruby (e.g., Cucumber), JavaScript (e.g., Cucumber-JS), or Python (e.g., Behave) may be more suitable. Tools that run as separate applications may be good choices, as well (e.g., SoapUI, FitNesse). Developers can use them on their Windows development boxes, and the same tools can run on various target platforms.
Considerations 3 and 4 suggest we want tools that provide straightforward ways to organize and re-organize test cases, and to select subsets of the test suite for execution based on any criteria we want to define.
Consideration 5 suggests we want tools that can handle SOAP, REST, and custom APIs without too much trouble.
Consideration 6 suggests we want tools that support test case definition in a form that is understandable to both technical and non-technical stakeholders.
Consideration 7 suggests we want tools that can support example-based and property-based testing.
Expressing Examples with the Given-When-Then Pattern
Any behavioral checks will specify preconditions, an action against the system under test, and expected postconditions. The Given-When-Then pattern is widely used to state preconditions (Given), actions (When), and postconditions (Then) for behavioral examples.
Gherkin is a popular language for expressing examples based on the given-when-then pattern. Here is the same example we used above for checking the usage help for the RPN calculator service:
Feature: Reverse Polish Notation calculator service
Scenario: As a person, I want to know what I can do with the RPN service.
Given I want to know how to call the RPN service
When I invoke the RPN service
Then I receive usage documentation
Here’s a snippet of code for Cucumber-JVM that runs the examples (omitting boilerplate Java code):
Given("^I want to know how to call the RPN service$", () -> {
valuesToPush = EMPTY_STRING;
});
When("^I invoke the RPN service$", () -> {
jsonResponse = get(RPN_SERVICE_BASE_URI + valuesToPush);
});
Then("^I receive usage documentation$", () -> {
assertTrue(jsonResponse
.getBody()
.getObject()
.getJSONArray("usage")
.getJSONObject(0)
.getString("description")
.startsWith("pass values in postfix order"));
});
Most of the tools mentioned above can parse gherkin examples, and the code to execute them is roughly similar to this Java example.
Considerations for Choosing UI Testing Tools
If we assume once again that we need to support a large corporate IT environment, then the considerations listed above for API checking tools also apply to UI checking tools. UI checking can be considerably more complicated than API checking. Additional considerations include:
- Timing issues – different elements of a web page may be served asynchronously. Network delay can be variable and unpredictable.
- Browser implementation differences – different browsers, different versions of the same browser, and behaviors of a browser on different platforms create complications in defining stable and reliable automated checks.
- Responsive design issues – with responsive design, the elements on a web page change position, shape, or size, and may disappear altogether, when the user re-sizes the window or depending on the state of the user’s interaction with the application.
- Accessibility features – special features to support the needs of people with different kinds of disabilities must be handled.
- Internationalization and localization – UI checks must handle internationalization features (under the covers) and/or localized content.
- Mobile devices – automated checking tools must be able to access various kinds of mobile devices and device simulators.
- Legacy UIs – automated checking tools must be able to access command-line applications, WinForms, Java Swing, Tandem/HP Pathway, and other legacy UIs, as well as emulating IBM 3270 and 5250 terminals (in a platform-agnostic way).
Example-based testing provides concrete behavioral examples for checking deterministic results. It can also check nondeterministic (statistical) results.
Examples are readable by all stakeholders, for purposes of system documentation, when written as Given-When-Then scenarios or in a tabular form. A tool that supports both formats would be preferable to one that supports only one format.
Best of Breed?
To minimize the number of different tools in the environment, it would be preferable to find a tool that handles API and UI checking equally well. In the author’s experience, the tool that offers the widest range of options and the simplest customization path is the Ruby implementation of Cucumber.
Here is a set of examples for a trivial “Hello, World!” application that illustrates the tabular form of Gherkin:
Feature: Say hello
As a friendly person
I want to say hello to the world
So everyone will be happy
Scenario Outline: Saying hello
Given I meet someone who speaks <language>
When I say hello
Then the greeting is <greeting>
Examples:
| language | greeting |
| English | "Hello, World!" |
| Spanish | "¡Hola, mundo!" |
| Japanese | "こんにちは世界" |
| Russian | "Здравствуйте, мир!" |
The Ruby code to make this executable looks like this (omitting boilerplate code and helper methods):
Given(/^I meet someone who speaks (.*?)$/) do |language|
visit_page HelloworldPage
@language = language_key language
end
When(/^I say hello$/) do
@current_page.selector = @language
end
Then(/^the greeting is "(.*?)"$/) do |greeting|
expect(@current_page.greeting).to include greeting
end
Ruby is a cross-platform language. Cucumber itself is a lightweight framework for running examples. Ruby libraries known as gems provide add-on functionality. Gems exist to support a wide range of API standards, markup languages, terminal emulation, assertions and mocks, and ancillary features such as formatting test case output, logging, dealing with web timing issues, and taking screenshots. In addition, practical support for property-based testing is already available. Ruby is an easy language to learn and configuring Cucumber to use various gems is straightforward.
By including the appropriate gems in the test project, it’s no more difficult to run examples against iOS apps, Android apps, or IBM CICS applications than it is to exercise a Web-based “Hello, World!” app.
It’s a logical choice for organizations that support services that offer multiple methods of invocation, as the code for setting up preconditions and specifying expected postconditions can be re-used.
Comments (7)
Peter Thomas
Dave – I’m not sure if you have looked at Karate – https://github.com/intuit/karate – and I think it addresses most of the points you bring up.
Karate is being used by teams to successfully mix Selenium / WebDriver tests into an API testing suite (see link below).
I also have to mention that I’m not a fan of using BDD for API tests: https://stackoverflow.com/a/47799207/143475
Thanks Peter, I’ll have a look at Karate. I read the README on the Github repo, and at first blush it doesn’t look particularly different from Gherkin interpreted with anyone’s favorite parser (Cucumber or other). So I’m not sure (yet) what the advantage is. I plan to play with it and find out.
Re using BDD for API tests, I read your note on SO and I can relate to it. IMO there’s a difference between doing BDD as such and using a tool that happens to be used for BDD. In the context of choosing tools for an enterprise environment, one of the considerations is to minimize the number of different tools people have to deal with every day. The problem I was thinking of when I wrote the post was that people often take that concern to an extreme, and assume they need to use tools that are all written in the same language for everything they do. Unfortunately, people often end up with an investment in tools and test suites that are hard to live with because they’ve shoe-horned the wrong tool into the mix. I understand that’s basically your concern with using Cucumber for API testing, too, and I appreciate that point of view. We may differ about where to draw the line.
Personally I don’t have a philosophical or practical problem using the same tool for both API testing and UI testing. It makes for one less tool in the pile. The specifics of the kind of testing we’re doing will differ, but that in itself doesn’t make a second tool necessary. That’s a question of what we are doing, not the tool we are using. IME someone who doesn’t understand the differences in various kinds of automated testing won’t be saved by handing them yet another tool.
Gherkin has very few “rules” and it’s easy to structure the examples in a way that’s appropriate to the task at hand. In one context, the examples can reflect business-level domain language. In another context, they can use language appropriate for a technical audience working with an API. Any gherkin parser can be used to write steps for both those situations. There’s no need for two tools to support those two activities.
Regarding your warning to expect endless arguments, I will suggest it’s possible to worry too much about hearing arguments about the way the Gherkin is written from people who may not deeply understand the buzzwords they’re arguing about, and who have rigid notions of which tools support which practices. Those people will continue to learn as they progress in their careers. We can give them time and space to do so without getting pulled into useless debates. I tend not to worry about that too much.
I want to suggest another perspective about whether APIs are machine-facing or human-facing definitions. Clearly, they are machine-facing in that people can write code that interacts with them. At the same time, they are human-facing descriptions of how to write client code. I’m not really sure what the problem is with expressing examples of API interactions in Gherkin. Karate does that, as do numerous other tools that generally appear to be almost identical to one another. As a human, I find it easy to relate to examples of API interaction written in Gherkin. The underlying step definitions are pretty easy to write and read, as API interactions are inherently much simpler than UI interactions. Almost all of them amount to setting up either a REST or SOAP request and then plucking a couple of values out of a response in JSON or XML. Every programming language has libraries to handle those details for us. So I have to wonder whether Karate is a solution in search of a problem.
I’ll check Karate out and see what value it adds over the myriad of existing tools already available. If it’s really a breakthrough, I’ll happily say so and probably adopt it in my own work. If it seems to be another Gherkin interpreter to add to the already-long list of same, I hope you’ll understand that I’ll happily say that, too, with no disrespect intended.
Thanks for the feedback!
Peter Thomas
Thanks for the (wow) detailed reply. We certainly disagree on a few points, but I really appreciate that you intend to take a closer look at Karate and with an open mind.
> Almost all of them amount to setting up either a REST or SOAP request and then plucking a couple of values out of a response in JSON or XML
I think you over-simplify things here because IMHO you are missing the part where you do assertions on the responses. Here is an example of Karate syntax: https://gist.github.com/ptrthomas/2a1e30bcb4d782279019b3d5c10b3ed1
If you are up to the challenge, I’d like to see the equivalent in Cucumber and Ruby step-defs :P
Actually, it would be more interesting to implement the DSL using a language that is better suited to writing DSLs than Java. But we won’t do that here on the blog.
Bobman
I agree with your points on using Gherkin/Cucumber (or I wouldn’t be here) but disagree with your arguments about what language to implement the Cucumber stuff in.
In my case, we are constrained by schedules to learn new languages. I agree with you that engineers are smart enough (and may actually be interested enough) to learn new languages, but when you have a deadline that doesn’t take learning into account, you stick with what you know because that is where you are more productive.
In the end, we work for companies that want us to be productive. Hopefully, they are interested in our (engineers) personal development as that benefits us all in the long run, but that is not always the case in the short run.
David Nicolette
I might suggest that when you have a deadline that doesn’t take learning into account, you have a management problem.
Mark Scholl
Hi David,
I agree with comment on management problem,
I very much appreciated the clarity of your valuable article.
Thanks,
Mark Scholl