Build a CI/CD Pipeline in the Cloud: Part One
Hey, here’s something fun we can do together: Let’s develop a microservice and build an end-to-end continuous integration/continuous deployment pipeline in the cloud with no locally-installed development tools.
This Part 1 of a four-part post. Here’s what we’ll do:
- Part 1: Clarify scope, answer a few questions, and sign up for some online services we’ll be using during the exercise
- Part 2: Configure version control, development environment, dependency manager, and run manager.
- Part 3: Test-drive the initial functionality of our microservice.
- Part 4: Configure continuous integration, static code analysis, and automated deployment.
I can hear you saying: I’m not a developer, so this post isn’t for me.
This is meant to be a pretty friendly walkthrough of the basic elements of a functioning, cloud-based continuous delivery pipeline. If you’re a Project Manager, Scrum Master, Product Owner, Agile Coach, or anyone else with a stake in software development and delivery, this could be a way for you to get a sense of the world developers live in.
If you’re a developer and you want to get your feet wet with some configuration and deployment stuff, this could be fun for you. If you’re an infrastructure engineer and you want to try your hand at writing some code, this could be fun for you.
I can hear you saying: Well, okay, but…
What’s a Microservice?
The term service generally means an application (or some function of an application) that can be invoked over a network to retrieve a result. For instance, if you invoke the OpenWeatherMap service to get weather information for London, UK, like this…
http://samples.openweathermap.org/data/2.5/weather?q=London,uk&appid=b6907d289e10d714a6e88b30761fae22
…the service might return a result like this:
{
"coord":
{
"lon":-0.13,
"lat":51.51
},
"weather":
[
{
"id":300,
"main":"Drizzle",
"description":"light intensity drizzle",
"icon":"09d"
}
],
"base":"stations",
"main":
{
"temp":280.32,
"pressure":1012,
"humidity":81,
"temp_min":279.15,
"temp_max":281.15
},
"visibility":10000,
"wind":
{
"speed":4.1,
"deg":80
},
"clouds":
{
"all":90
},
"dt":1485789600,
"sys":
{
"type":1,
"id":5091,
"message":0.0103,
"country":"GB",
"sunrise":1485762037,
"sunset":1485794875
}
"id":2643743,
"name":"London",
"cod":200
}
You can invoke most services just like that, and view the result as it is presented. But normally the expectation is you will write a piece of software that acts as a client to the service. That piece of software will help the user formulate the request and will present the results in a friendlier form than the raw text. After all, most people don’t want to see that the sun will rise at precisely 1485762037 in the morning, or that the current temperature is 280.32 degrees. (That is a bit chilly. Better grab a jacket!)
The prefix micro- implies “small.” But the idea isn’t just that the service is small. The idea is to design an application as a set of small services that can be deployed independently of one another. The term microservice architecture is meant to distinguish this approach from previous design approaches, which in hindsight we call monolithic. In a monolithic application, you have to deploy the whole thing even if only one small part of it has changed.
It’s also difficult to reconfigure a running monolithic application to handle dynamic changes in workload or other environmental factors. If a monolithic application experienced an increase in demand for one of its functions, you’d have to spin up additional instances of the entire application. With a microservices architecture, you can scale and de-scale individual services. This can save both cost and effort.
What’s Continuous Integration?
As a software team makes changes to a code base, different team members soon find themselves working with modified versions of the code that are all out of sync with each other. With older software development methods, the various team members integrated their changes only after they had made significant modifications. This often led to difficulties in merging the various changes without losing code or breaking functionality.
With contemporary methods, team members commit very small changes to version control very frequently, throughout the day. Each time they commit they also update their local copy of the code base from version control, so that they have the latest version. In this way they integrate their changes very frequently (in a sense, “continuously”) rather than accumulating a large set of changes that may be more difficult to integrate all at once.
What’s Continuous Deployment?
Continuous deployment is a similar concept to continuous integration, except it pertains to deploying the application to production rather than to integrating code changes. Rather than compiling weeks or months of modifications before migrating them all to production at once, we now prefer to deploy small changes frequently.
As a single small change may not completely implement a new feature, we use so-called feature toggles to mark some sections of code as “active” or “inactive,” so it will be safe to move incomplete modules into the production environment.
What’s a Delivery Pipeline?
A delivery pipeline consists of the series of steps necessary to take code from development all the way through to the production environment. With older methods, this was almost always done manually. People didn’t speak of it as a “pipeline” because it looked and felt like a bunch of disconnected activities. The activities usually took place in a certain sequence, but the whole process was not organized holistically and different activities were often assigned to separate teams that specialized just in the one task.
Today, most or all these steps are often fully (or almost fully) automated. When a developer commits a code change to the version control system, that act triggers a series of automated steps. Assuming no errors are detected along the way, and assuming automated deployment makes sense from a business perspective, the code change could find its way into production without any human intervention.
It’s something like this:
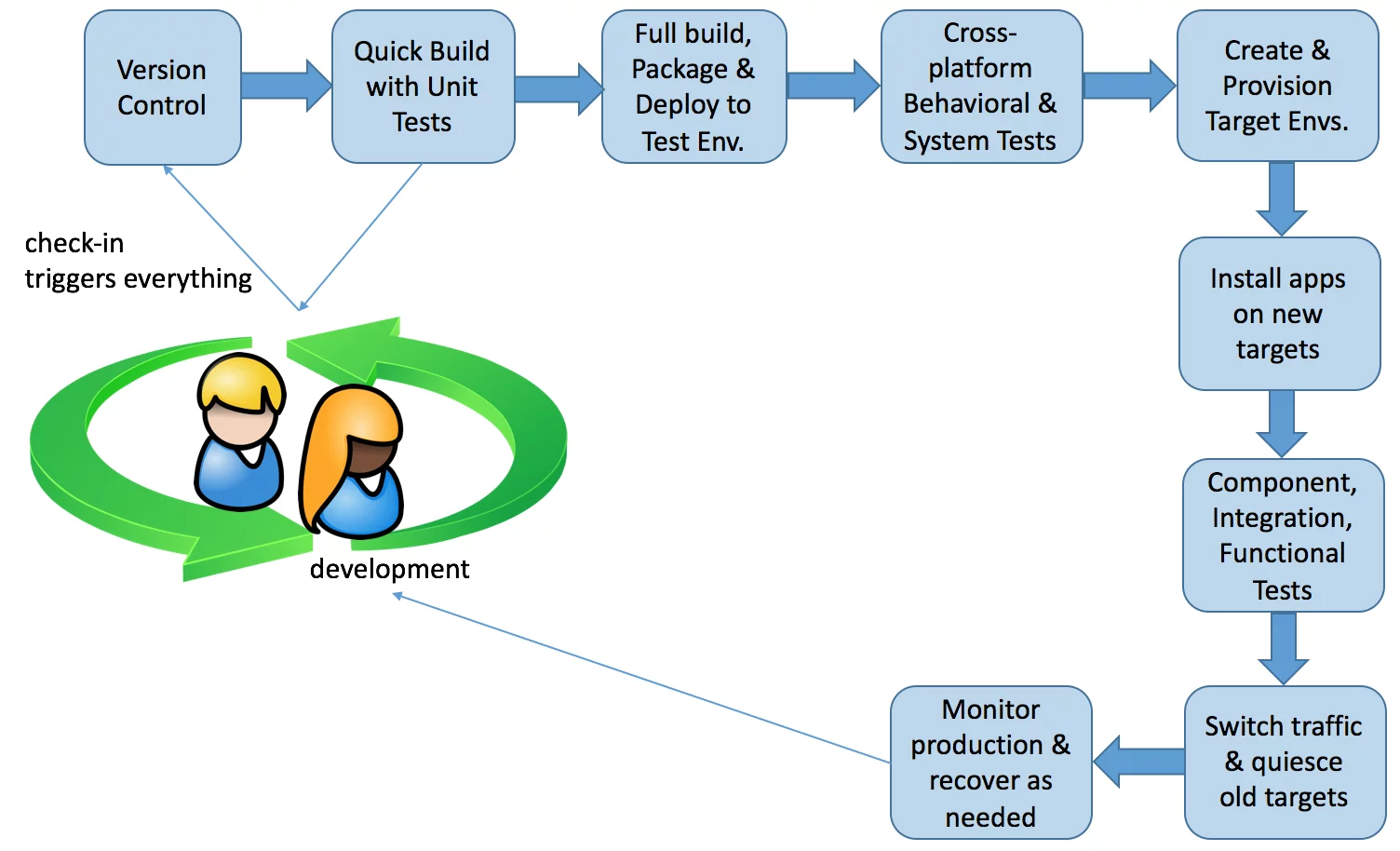
What are We Going to Do?
We’re going to put together something like the pipeline illustrated in that picture. We won’t have quite so many steps, as we’ll only have one level of automated testing. Some of the steps will be handled for us by the online facilities we’ll use. We also won’t experience merge conflicts, as we won’t be making changes to our service concurrently with other people. We’ll dispense with containers and container management tools, as well. It will be a subset of the sort of pipeline you might set up for real production operations in an enterprise IT situation. It will include all the main moving parts of such a pipeline, so you can get a practical feel for it.
Let’s Get Set Up
Here’s what you’ll need:
- A free account on Github. This will be the version control system.
- A free account on Code Anywhere. This will be the development environment.
- A free (Open Source) account on Travis CI. This will be the continuous integration service.
- A free (Open Source) account on Code Climate. This will be the test coverage and static code analysis service.
- A free account on Heroku. This will be the production environment.
Your homework assignment between now and the publication of Part 2 is to sign up for those online services. Play around with them a bit and explore the capabilities they support. Do some reading in preparation for getting started with the hands-on activity.
I’ll be back soon!
Comment (1)
Nick
The cloud tools are frictionless. I use these but use Cloud 9 for the ide and bash shell and CircleCI for the build pipeline. Never been a simpler time to code.