Questioning Agile Dogma


When I first learned about Agile methods in 2002, the principles seemed to offer an ideal solution to many organizational issues common at the time. When I applied those principles in real-world situations, they worked remarkably well. Today, some of the same principles seem to present impediments or unnecessary challenges for many teams and organizations. How can the same principle be a good idea in 2002 and a bad idea in 2019? What has changed?
It’s time now to move forward to the next level of proficiency in software delivery; what we might call “post-Agile.” A lot more is possible than was imagined when “Agile” was first defined. The first step must be to apply one of the fundamental principles of Agile thinking: Question everything. Let’s begin with some parts of the Agile canon itself.
A number of ideas are associated with “Agile,” including some that aren’t specifically mentioned in the Agile Manifesto. I’d like to consider the following in this post:
- Sustainable Pace
- Stable Team
- Dedicated Team
- Team Spaces
- Time-boxed Iterations
Sustainable Pace
A team should be able to maintain a steady and predictable rate of delivery for an extended period of time, often stated as “indefinitely.”
Problem Addressed
There was a common practice known as the “death march,” in which projects began with a fixed timeline but (often) with few if any of the resources the delivery teams would need (such as servers, test environments, software licenses, access rights to key systems, etc.) and limited access to key stakeholders, who were already coping with death marches that had started previously, and were not available to support the teams. High WIP levels and failure to recognize delivery capacity, identify scarce resources, and consider estimates led to intense pressure to deliver late in the project schedule.
As the deadline for a given project loomed, the teams went into “death march” mode, in which they attempted to compensate for all the wasted time up to that point (as well as to try and meet unrealistic expectations) by working themselves to exhaustion. A recovery phase followed (often unofficially, in the form of sick leave or informally-approved, untracked, and unacknowledged “comp time”) before the next death march cycle began. Because the recovery phase was not officially recognized (typically due to time reporting rules that prohibited honesty regarding overtime), management missed the opportunity to learn from experience and repeated the death march pattern again and again.
Sadly, there are those who see the death march pattern as a magic bullet to enable them to squeeze an arbitrary amount of work out of their delivery teams on literally any schedule they choose. John Boddie’s book, Crunch Mode: Building Effective Systems on a Tight Schedule, provides a recipe for doing this on purpose. It includes advice about planning for employee burn-out and burning them out quite deliberately. In contrast, Edward Yourdon’s book, Death March: The Complete Software Developer’s Guide to Surviving ‘Mission Impossible’ Projects, describes the harm the death march pattern causes and advises software development teams on how to survive it. Survival is the best the teams can hope for. The business can’t hope for anything at all, as the death march approach doesn’t work.
Business Impact
The combination of high WIP (work in process), multiple and uncoordinated project assignments per individual, lack of coordination of scarce resources, and inattention to cross-team dependencies during planning led to unpredictability in software delivery. No one was able to determine accurately how long it would take to provide the business with any given operational capability if that capability depended to any extent on software being developed and delivered.
By setting a sustainable pace for the work, teams were able to maintain a steady rate of delivery, leading to greater predictability and hence easier planning. Additional benefits included reduced staff stress, leading to longer retention and lower turnover rates, improved employee engagement, more-positive attitudes, and the unleashing of people’s creativity. We always observe a ripple effect of secondary benefits, once sustainable pace has been achieved.
Diminishing Returns
When a nominally-agile process becomes established, teams fall into a rote pattern of grinding out a never-ending series of User Stories. The situation is so common that it has names. Zombie Scrum describes the impact on delivery teams. See this and this for more information. From a business perspective, the situation is called the delivery trap, the velocity trap, and similar names. This refers to the focus on the speed and/or quantity of output produced, without regard for business value delivered or for product quality.
Next Steps
Many organizations have cured themselves of the death march pattern, and there is no longer a need to impose a “remedy” for it. We can now move on to the next level of team performance by enabling such things as slack time, learning time, periodic breaks and rests, swapping team members, and other mechanisms to break up the monotony of sustained work. (Note: sustainable is good; sustained is not.)
LeadingAgile Approach
Every organization is unique, and the path forward will naturally vary. However, we’ve observed some general patterns that tend to be common across many organizations. With respect to the problem of sustainable pace, it’s often the case that organizations are operating chaotically in an attempt to deal with rapidly-changing customer demand and market conditions, using structures and processes designed for an era when things moved at a more deliberate pace, and when the direction of the market was more predictable than it is today. They may have attempted an “agile transformation” of one kind or another, but lacked the necessary organizational foundations to make it work well or last long.
Based on our compass model, organizations still experiencing death marches tend to be operating in the Predictive-Emergent quadrant, in which methods based on prediction of known outcomes are applied to problems whose solutions are emergent in nature (not known in advance); a kind of “impedance mismatch,” if I may use the term loosely.
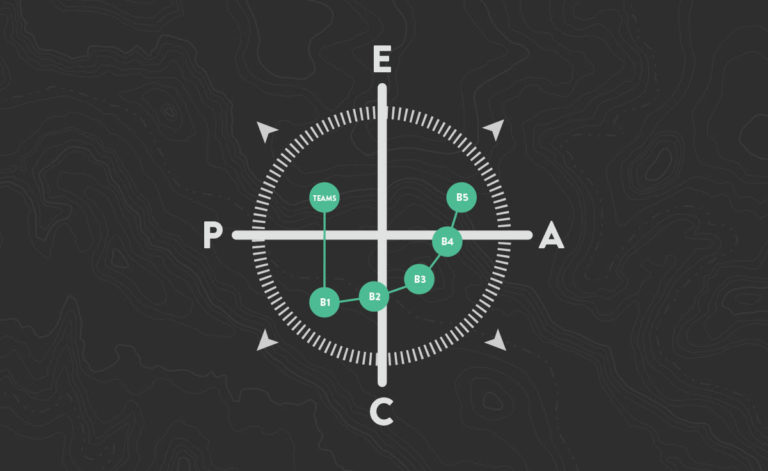
With appropriate customization, the general approach is to guide the organization into the Predictive-Convergent quadrant, to an operating state we call “Basecamp One.” The goals are to stabilize the delivery system, establish meaningful metrics, and achieve planning predictability. With this as a foundation, further progress toward more-effective delivery of business value can be made.
Without such a foundation, moving directly to lightweight “agile” methods (depicted on the right-hand side of the compass diagram, labeled A for Adaptive) often results in the wrong things being delivered with low quality faster than before. In these cases, the death march anti-pattern often remains in place; the difference is that the damage is done faster.
When you hear people say, “We tried agile and it didn’t work,” this is often what has happened in their organizations. Ron Jeffries’ classic article, “We Tried Baseball and it Didn’t Work”, is an amusing and yet chillingly accurate description of this situation. For any approach to “work,” the necessary conditions for success must be in place.
To prevent the Zombie Scrum or Delivery Trap phenomenon, our operational model keeps planning, execution, and tracking coordinated horizontally across dependent Delivery Teams and vertically through the Portfolio, Program, and Delivery levels. All stakeholders (including Delivery Teams) are involved with backlog refinement and value identification. In this way, Delivery Teams never see the world as a never-ending series of context-free tasks. Instead, they become an active part of the business solution.
We also advise organizations to build learning time into the normal work flow at the Delivery Team level, so that practitioners can keep their skills sharp, learn about advancements in technology, and maintain a high level of engagement.
Stable Team
A team stays together for a long time (essentially, “permanently”). Projects are assigned to stable, pre-existing teams.
Problem Addressed
This was a reaction to the common practice of forming a new team for each project. People had to repeat the “storming, norming, performing” pattern for each project. People had little opportunity to learn to work effectively together as a unit, to extend trust to one another, and other useful aspects of effective team-based work.
Business Impact
The overhead of repeated team-forming affected delivery schedules by introducing delay into every initiative. Around the time a team was beginning to “gel” and function well together, they would complete their project and the individual team members would be reassigned to new teams, to begin the process again. As a result, the organization never benefited from the full potential of the technical staff. Staff effectiveness was artificially suppressed by the logistical and psychological stresses of forming and re-forming teams over and over again endlessly.
When the stable team concept was put into place, teams gelled into cohesive work units in which tight collaboration was enabled by a higher level of mutual trust than had been possible before. People had time to get used to each other, discover one another’s strengths, and learn to collaborate effectively to maximize those strengths and wash out any weaknesses. As a result, product could be delivered in less time and with higher quality than before, and staff morale was improved.
Diminishing Returns
With long-term teams now the norm in most organizations, the downsides of stable teams are beginning to manifest. These include a lack of opportunity to learn other systems in the organization and/or other technologies besides the ones used for the application the team supports. This can result in disengagement, turnover, marginalization, “invisibility” for purposes of promotion, and career stagnation. In response, many individuals seek opportunities with other employers, leading to a higher turnover rate and all the costs associated with that.
In addition, in larger organizations, we’ve observed an insidious effect of stable teams that isn’t evident in smaller organizations. Given a heterogeneous and complicated technical infrastructure, multiple different platforms and programming languages, and a need for specialized skills in areas where skilled personnel are rare (rules engines, ETL tools, call center platforms, database systems, network engineering, security, etc.), it isn’t feasible to include all the skills necessary to deliver on every team. Those with rare and specialized skills tend to be organized into service teams that support multiple delivery teams.
When agile consultants advise organizations to form small teams, the problem worsens. Where a single team of 15 might be advisable, instead there are three small teams, each with its own backlog and priorities. This increases the difficulty of coordinating the work.
Many organizations new to agile methods tend to exacerbate the problem by attempting to standardize the composition of their “agile” teams; regardless of nature of the work each team performs, every team has the same composition (for instance, 4 programmers, 2 testers, and 1 analyst). Not all types of work call for the same skill sets in the same proportions and many types of work require the services of specialists at least some of the time. Thus, more cross-team dependencies are created.
The result is a multitude of cross-team dependencies, which is one of the greatest causes of delay, error, and re-work in any delivery system.
Another common novice mistake is to assign a Product Owner to every small team. These individuals then form personal management fiefdoms competing with one another for recognition and opportunities for career advancement. As the Product Owner role is often poorly understood, the competition quickly takes the form of political infighting.
In reality, one product may be supported by several teams. What is needed is a Product Manager responsible for the business value of the product. One of the roles or functions of the Product Manager is that of Product Owner, in the Scrum sense. But organizations trying to “go agile” often equate the Product Owner role with a separate individual, and assume each small team needs their own. This creates needless organizational friction that reduces delivery effectiveness.
I suspect this misconception came about because “agile software development” originated in very small organizations, or small parts of larger organizations, in which a single autonomous delivery team supported a single product, and a decision-maker responsible for that product was readily available to work with the delivery team. This is not usually feasible in larger organizations, and the canonical agile model doesn’t quite fit there.
Next Steps
In mature agile organizations, we have observed that the technical staff builds mutual trust and learns to collaborate effectively overall, not merely within each separate small team. When they come together in different combinations to meet various objectives, they have already “normed” and they don’t repeat the old-school team-forming steps.
So, if a piece of work comes up that calls for 1 senior programmer, 1 junior programmer, 2 testers, and a database specialist; any five staff members matching those descriptions can work effectively together to complete it. If the next piece of work calls for a different set of skills, then the appropriate individuals can self-organize into a temporary team without any loss of effectiveness.
With the “matrixed organization” problem solved (see Dedicated Team, below), we can safely form teams around emergent demand. On the surface, this looks very much the same as forming a new team for each project, but it’s informed by the lessons learned and the general cultural changes accomplished by the agile movement to date. With upcoming work visible to all, staff can self-organize to form teams to address the work. This approach retains the advantages of the “agile” approach while mitigating (or eliminating) the problems of long-term stable teams.
LeadingAgile Approach
Given the characteristics of organizations operating in the Predictive-Emergent (PE) quadrant, you can well imagine that the next steps depend on some fairly ambitious prerequisites.
In PE organizations, it’s often the case that no one has a clear picture of the overarching business goals. Even top leadership cannot articulate a short list of key strategic business capabilities the organization needs to cultivate. Leadership tends to think in terms of one-off point solutions to immediate tactical issues. The priorities are constantly changing, not for the “right” reason of adapting to (or driving) market changes, but for the “wrong” reason of not really understanding what to do next.
Every time leaders smell the smoke from a different one of the many fires burning around them, they change priorities. Delivery teams feel as if everything is an emergency and nothing is really important, as it makes no difference whether they solve today’s problem or not. By tomorrow, today’s emergency will have been forgotten. So, there’s no benefit in breaking your back to try and get anything done.
In many cases, the organization has more than one “leader” who all have equal decision-making and budgetary powers. This usually comes about for historical reasons; each of these individuals has contributed to the company’s growth in some significant way and has been rewarded with power. But they are not coordinated. In effect, the organizations have more than one “top priority,” and no mechanism in place to break ties.
There’s no way to make the “upcoming work visible to all,” because there’s no clear definition of what the organization ought to be doing. Delivery teams wouldn’t know how to self-organize effectively around the work, either, as they have never been treated that way before and have no experience with the approach.
Our approach to this is to bring the organization into the Predictive-Convergent (PC) quadrant so that they can build the foundation to enable business agility. The first step has to be to bring the delivery process under control and measurement. Otherwise, no one can know what to improve, how to improve it, or how to measure the impact of any attempted improvements.
With Basecamp One as a foundation, the organization can begin to incorporate further agile and lean ideas and grow toward greater business agility. Whether the organization follows the general path through the Basecamp model or charts a custom path, it’s crucial that they establish a firm foundation on which to base each successive improvement. There is no single step directly from chaos to a smoothly-functioning lean/agile operation. A mindful progression of steps is necessary.
Dedicated Team
A stable team works on exactly one thing at a time.
Problem Addressed
From the 1970s through most of the 1990s (and continuing to the present day in many larger organizations), it was standard practice to assign individuals to multiple projects concurrently, mixing and matching people according to their roles. The set of individuals assigned to each project was nominally a “team,” but it was not a cohesive team that functioned in the way we normally visualize (similar to Patrick Lencioni’s notion of a team).
This approach is so fundamentally illogical that it may be difficult for you to imagine unless you’ve worked in such an organization. It was not unusual for a person in roles like Business Analyst, Application Architect, or UI Designer to be assigned to 30 or more projects concurrently, and expected to divide their time appropriately across them. More narrowly-defined roles would have fewer concurrent assignments, but still too many to be effective.
One Developer, Joanne, might be on Project A 50%, Project B 25%, and Project C 25%, with Project A as her top priority. At the same time, Developer Samuel might be on Project D 75%, Project E 15%, Project F 5%, and Project A 5%, with Project D as his top priority and Project A as his lowest priority. Tester Betty is assigned to five different projects, 20% each, and Project A is her third priority.
Imagine how smoothly Project A progresses. When Joane hits a blocker on Project A, her highest priority, that requires Samuel’s assistance, she has to wait until he finds time to pay attention to Project A, which is his lowest priority. Assuming Project A ever gets anywhere, Betty may or may not have time to test it. Project A is not her highest priority.
Now imagine a portfolio of 200 or 300 projects being managed in this way.
Business Impact
The most obvious business impact was extended lead times. The delivery system was so clogged with “waits” that the work could hardly move at all. Almost every minute of every day, every piece of work in process was waiting for something, and priorities were not coordinated.
Management could not see the problem, for a couple of key reasons. First, the project management tool showed every task that had been started as “in progress,” even if the work was actually halted. Second, the rules for tracking people’s work hours prohibited staff from entering the true number of hours they applied to each of their projects. Joanne was blocked by the time tracking system from logging more than 25% of her standard work hours toward Project C, because she was officially assigned to Project C for 25% of her time. Yet, if she needed to “fill up the buckets” in order to show 40 hours of work for the week, and time was available for Project C, she would log her remaining hours to Project C, even though she had been working on Project A. All the management systems were set up to validate manager’s assumptions and plans rather than to reflect reality.
By establishing stable teams and then ensuring that each team could focus on just one thing at a time, some of these wait states were eliminated from the delivery system. There may still be cross-team dependencies that affect lead times, but the situation is improved significantly. An application development/support team could focus on one project at a time. A service team would still support multiple application teams but could focus on just one area of service.
Imagine Project A in this world: Joanne, Samuel, and Betty are all on the same team, and their only assignment is Project A. When Joanne needs Samuel’s help, he’s right there. When they have code ready to test, Betty is right there. And if she finds any problems, Joanne and Samuel can address them immediately. No delays, no blockers, except for service teams. Even better: Betty is in the same room, working directly with Joanne and Samuel before they start coding. Together they will design a solution that is easy to test and has quality built in from the outset.
Reducing the number of cross-team dependencies reduces lead times. By enabling people to focus on what they were doing rather than jumping from one thing to another all day, as well as enabling close collaboration across roles, quality is improved, as well.
Along with measures such as dedicated teams, the introduction of agile and/or lean methods in an organization changes the way projects are managed and tracked. These changes mitigate or solve the issue of managers being unaware of what’s really going on. First, “information radiators” or “visual management” tools, which may be tactile, electronic, or both, provide everyone who has an interest in a project with up-to-the-minute status of how the work is progressing, including any blockers or other issues affecting flow. Second, rather than keeping track of how busy each individual staff member is, metrics are focused on how well work items are flowing through the system. These changes provide management with meaningful and useful indicators of progress and issues.
Diminishing Returns
The suite of products supported in most organizations are logically and sometimes organically connected with each other; they don’t stand alone in the world. That means there are times when product-aligned teams must coordinate work that affects multiple products. In these cases, the spectre of cross-team dependencies rises again. Other than that, using dedicated teams hasn’t resulted in the kind of downside impact that some other agile practices have done.
However, one area of general improvement is to shift from a project focus to a product focus. Rather than working on one project at a time, each stable team becomes dedicated to supporting a single product on a full-time basis.
Once that shift occurs, the team is subject to the same downside risk as with stable teams: The loss of opportunity to work on different things and learn new skills and technologies, and loss of “visibility” for recognition and promotion.
Next Steps
The remediation for this problem is much the same as that for the stable team problems. Allowing staff to self-select available work and to self-organize around emergent demand opens the door for working on different things and learning new things, which keeps the technical staff engaged and energized. It also enables temporary teams to be formed around emergent demand, which mitigates the cross-team dependency problem.
LeadingAgile Approach
I mentioned a shift from project-centric to product-centric operations. That is easier said than done, and will probably be infeasible for most organizations that are operating in the PE quadrant or that have not progressed beyond Basecamp Two in the LeadingAgile transformation model. Prerequisites must be in place for this to work well, and it takes time and focused effort to establish those prerequisites.
The shift to a product focus affects all of the three main “things” that we talk about: Structure, Governance, and Metrics.
Regarding Structure: Teams must be aligned with product value streams. Generic “development” teams that are treated as fungible resources that can receive work for “any” product on a per-project basis will not support this mode of operation.
Regarding Governance: Some potentially significant changes may be needed. The whole idea of when a product is “finished” changes with this approach. The idea that a piece of software is “in development” and therefore the work can be capitalized may become obsolete. A piece of software is considered to be “in production” as soon as the first vertical slice of functionality has been delivered, and simultaneously is “in development” throughout its lifetime. On a practical level, this usually means all costs associated with the product are expensed.
Farther-reaching changes to the funding model are also possible, in the nature of Beyond Budgeting and similar models, in which the annual budget cycle ceases to exist, and funding is adjusted on a periodic basis depending on changes in market conditions and/or organizational objectives and priorities, or based on the performance of each product in the live market. That is a characteristic of Basecamp 4 and 5 operations.
Regarding Metrics: Rather than tracking performance to plan and other project-centric measures, the organization will be focused on the business performance of each product. Delivery performance will be tracked using Lean metrics such as Throughput, Lead Time, Cycle Time, and Cycle Efficiency, as well as financial measures of product performance. Conventional project-centric measures will be retired.
Changes of this scope cannot be dropped into place suddenly. Our approach is to guide the organization gradually in this direction, to the extent leadership wishes to go in this direction, through the Basecamp progression. This sort of change is unlikely to occur prior to Basecamp Three.
On a more tactical level, we deal with the emergence of cross-product dependencies by forming “virtual teams” temporarily. Say Product A and Product B require coordinated modifications to support a new business capability. While those modifications are being made, we may form a virtual team comprising key members of the dedicated Product A and Product B teams.
Given some of the other changes the organization will have gone through by this point, forming such teams is unlikely to cause thrashing (storming, norming, etc.), and the team members will be familiar with powerful collaborative work methods such as Mobbing and Pairing. Most of this would be infeasible in an organization still operating in the PE quadrant or struggling to reach Basecamp 1.
Team Spaces
Teams can be more effective if their physical workspace is organized in a way that facilitates collaboration. This was most simply expressed by the Extreme Programming principle, “sit together,” but there is a bit more to it than just that.
Problem Addressed
This was a reaction to the common practice of seating individuals in cubicles or other types of single-worker stations, such that interaction with co-workers was difficult.
Business Impact
The direct effects of isolating individuals included extended lead times, extended cycle times, delay, errors, re-work, miscommunication, low code quality, high risk of changing code, challenges in keeping skill sets up to date, and inconsistent technical standards and conventions throughout each code base.
Organizing the physical workspaces to enable effective collaboration improved outcomes in several ways. Lead times and cycle times were shortened, delays and waits (especially for information, clarification, or technical assistance) were reduced or eliminated (within each team), clarity of communication was improved, adherence to consistent standards and conventions was easily enforced, and people could help each other when they became stuck or confused. Code quality increased and the risk of changing code was reduced.
Diminishing Returns
The idea of a collaborative work space does not introduce any particular problems in organizations, provided the characteristics of such spaces are properly understood. Unfortunately, it has become commonplace to organize offices on the “open plan” model, whereby everyone can see and hear everything that occurs in a very large area. This format causes a lack of focus, challenges in communication, and (according to some studies) can even result in neurological damage. The “open plan” model is just a half-baked way to save money on furniture; it is not a bona fidecollaborative work space design.
Next Steps
The next steps are more in the nature of a correction than a replacement for collaborative work spaces. As long ago as the mid-1980s, Tom deMarco and Tim Lister described effective collaborative work spaces in their book, Peopleware: Productive Projects and Teams. Teams need a collaborative space for group work, such as mob programming and pair programming; semi-private spaces for brainstorming, problem-solving, and general discussion; and private spaces for one-on-one conversations, personal calls, reading, thinking, and emotional decompression (especially introverts). I’ve heard of a similar model called “caves and commons.” Like the Peopleware model, it recognizes the need for whole-team collaborative spaces as well as finer-grained spaces with different levels of privacy.
The corrective action is to replace the ill-conceived “open office” spaces with properly-configured collaborative work spaces for teams.
LeadingAgile Approach
One of the first, if not the first order of business is to form cross-functional teams. Part of that process includes organizing the physical work spaces for those teams so that they can function effectively. It is not possible for delivery teams to learn and apply agile and lean methods without having the proper physical spaces to work in.
Time-Boxed Iterations
By limiting the time for achieving a goal, we encourage teams to find ways to meet the goal within the specified time. This can result in both improved delivery and in general improvement, especially when combined with “heartbeat retrospectives.”
Work is divided into small deliverables that can be completed within a stipulated “time box” of fixed duration. A typical starting point is a time-box of two weeks, with a general improvement goal of shortening the time-box.
Each type of event in the team’s normal work flow is similarly time-boxed. For example, a planning session for backlog refinement my be time-boxed at one or two hours, depending on the team’s needs. The team’s retrospectives may be time-boxed at half an hour, one hour, or some other duration. When the team uses “promiscuous pairing” as a collaboration technique, the pairing sessions may be time-boxed to prevent stress and burn-out; a typical starting duration is 90 minutes. Some teams like to use the “pomodoro” technique, which calls for 25-minute working sessions followed by 5-minute breaks. The specific duration of each time-box is less important than the fact the work must stop when the time expires, even if the work is incomplete. The team then must seek ways to get the work done within the time-box next time. Thus, the time-box serves as a mechanism to inspire continual improvement.
Problem Addressed
Originally, the time-boxed iteration (called a “sprint” in Scrum) was a reaction to the common practice of “slippage” whereby people would give a delivery date, then move or “slip” the date again and again as they realized they would be unable to deliver by the given date. The general result of this practice was that organizations could not predict when anything was likely to be done. There was a belief that we were practicing “fixed scope with a variable schedule,” but in fact, the desired scope was often not completed regardless of moving the date outward again and again.
There were multiple causes for the problem, including high WIP, belief in “big design up front,” lack of feedback from customers/users, low participation in the process by customers/users either because they weren’t welcome (“don’t let them see the sausage being made,”) or they opted out (“we don’t have time to give feedback, just deliver what we asked for”), delays caused by cross-team dependencies, rework caused by poor communication, defects caused by poor technical practices, and delays caused by insufficient or wrongly-configured test and staging environments.
A second problem addressed by time-boxing was the lack of feedback from customers or internal consumers of a team’s work. To know whether the work is going in the right direction, it’s helpful for stakeholders (preferably users) to get their hands on whatever subset of functionality is available at the moment and try it out. They often think of things that would never had occurred to them working in isolation and trying to guess what it would be like to use the product. Time-boxed iterations generally require some functionality to be delivered in each iteration, even if it’s something trivial. This gives stakeholders something to examine, think about, and improve.
Business Impact
The timebox creates natural pressure to determine the most valuable subset of results to deliver early, rather than allowing the excuse of “slippage” for erratic and/or unpredictable delivery. Indeed, in the early years of Scrum, this aspect of timeboxed iterations was described in the literature in terms reminiscent of Death Marches: “Visualize a large pressure cooker. Scrum development work is done in it. Gauges sticking out of the pressure cooker provide detailed information on the inner workings, including backlog, risks, problems, changes, and issues. The pressure cooker is where Scrum sprints occur, iteratively producing an incrementally more functional product.” (from The Origins of Scrum, 1996). It wasn’t long after that time that proponents of Scrum started to use gentler language to describe the function of Sprints. Otherwise, it seems unlikely Scrum would have achieved the level of popularity it enjoys today.
Timeboxed iterations were the main mechanism to support the agile practice of fixed schedule and variable scope. They enable empirical forecasting of delivery performance, so that teams are able to predict with a reasonable degree of accuracy when they might be able to deliver any given amount of scope.
Diminishing Returns
As progress with agile thinking and practices has mitigated the problems of slippage and feedback, teams have learned to deliver consistently and predictably within a given timebox. The typical length of a software delivery timebox (known as an “iteration” or “sprint”) is two weeks, but there is nothing in the Agile Manifesto specifically about timeboxing or iteration length. The manifesto’s “preference to the shorter time scale” encourages teams to find ways to deliver with shorter timeboxes.
Once they are able to deliver reliably on a one-week cadence, most teams find the overhead of managing formal iterations or sprints to exceed the value of the timeboxes. They thrash, as they are unaware that “agile” allows for a continuous flow mode of work, without explicit timeboxes, once the problem addressed by the timeboxed model has been solved.
A problem observed in the field is that many agile practitioners regard the time-boxed iterative process model as sacrosanct, and as an “end state” for effective software delivery, rather than as a step toward a more-effective mode of operation. This can be a barrier to improvement beyond a certain point.
Next Steps
Once they have learned to deliver consistently within a short timebox, teams may be able to shift to a continuous-flow mode of work. In that mode, there is no fixed-length time-box, and teams address the single most important item on their plate at the moment. It is as close to a “single piece pull” model as will work for a software development process.
This is a highly efficient mode of work that involves a minimum of process-management overhead, but many teams are unable to use it effectively before they learn how to break the work down into small “vertical slices” and to deliver consistently within the boundaries of a time-box. If a team adopts a continuous flow model without having the requisite delivery discipline, there is a risk they can fall into the old problem of “schedule slippage.”
It’s a characteristic of lightweight methods in general that the lighter-weight the method, the greater the level of self-discipline required to use it effectively. “Lightweight” isn’t a free pass to stop managing the process.
LeadingAgile Approach
In general, we aim to adjust process steps, events and ceremonies, and technical practices as needed to support the organization’s next target Basecamp, according to their long-term improvement roadmap. When organizations are moving toward Basecamp Two, they may still be getting used to working within the constraints of a time-boxed process model, and they are not yet ready to operate without those boundaries. The time-boxes function like training wheels on a bicycle.
There are those who say it’s better for children to learn to ride their bicycles without training wheels from the beginning. Software teams can do the same, provided they pay due attention to the self-discipline necessary to deliver effectively. That is, they can begin with a continuous flow model from the outset, but if they can’t use it effectively they may be advised to move to a time-boxed process until they have cultivated the necessary skills and habits. In practice, this boils down to a choice between Scrum or Kanban (or a hybrid) at the delivery team level. We use Kanban at the Program and Portfolio levels in any case.
As organizations progress beyond Basecamp Two, and they have a goal to operate beyond Basecamp Three, we begin to shorten the iteration time-box and remove process management overhead activities, based on teams’ demonstrated ability to perform without these aids. In order to function effectively at the Basecamp Four or Five level, it is unlikely the organization will be able to support seamless continuous delivery while still using a strict time-boxed process model. They will have reached the point that the process management overhead of time-boxes exceeds the value added. It is important that delivery teams learn to deliver smoothly using a continuous flow process model, if the organization needs to move into the Adaptive side of the compass model.