Build a CI/CD Pipeline in the Cloud: Part Four
This is the final installment in a series of posts that walks you through test-driving a microservice and setting up a working continuous delivery pipeline to deploy it to the cloud automatically. Hail to you who have survived Parts 1 through 3!
In Part 1 we set the stage for our project and you received a homework assignment to sign up for several online services.
In Part 2 we configured our version control, dependency management, and run management facilities and started to get familiar with our development environment.
In Part 3, we test-drove the initial thin vertical slice of our application.
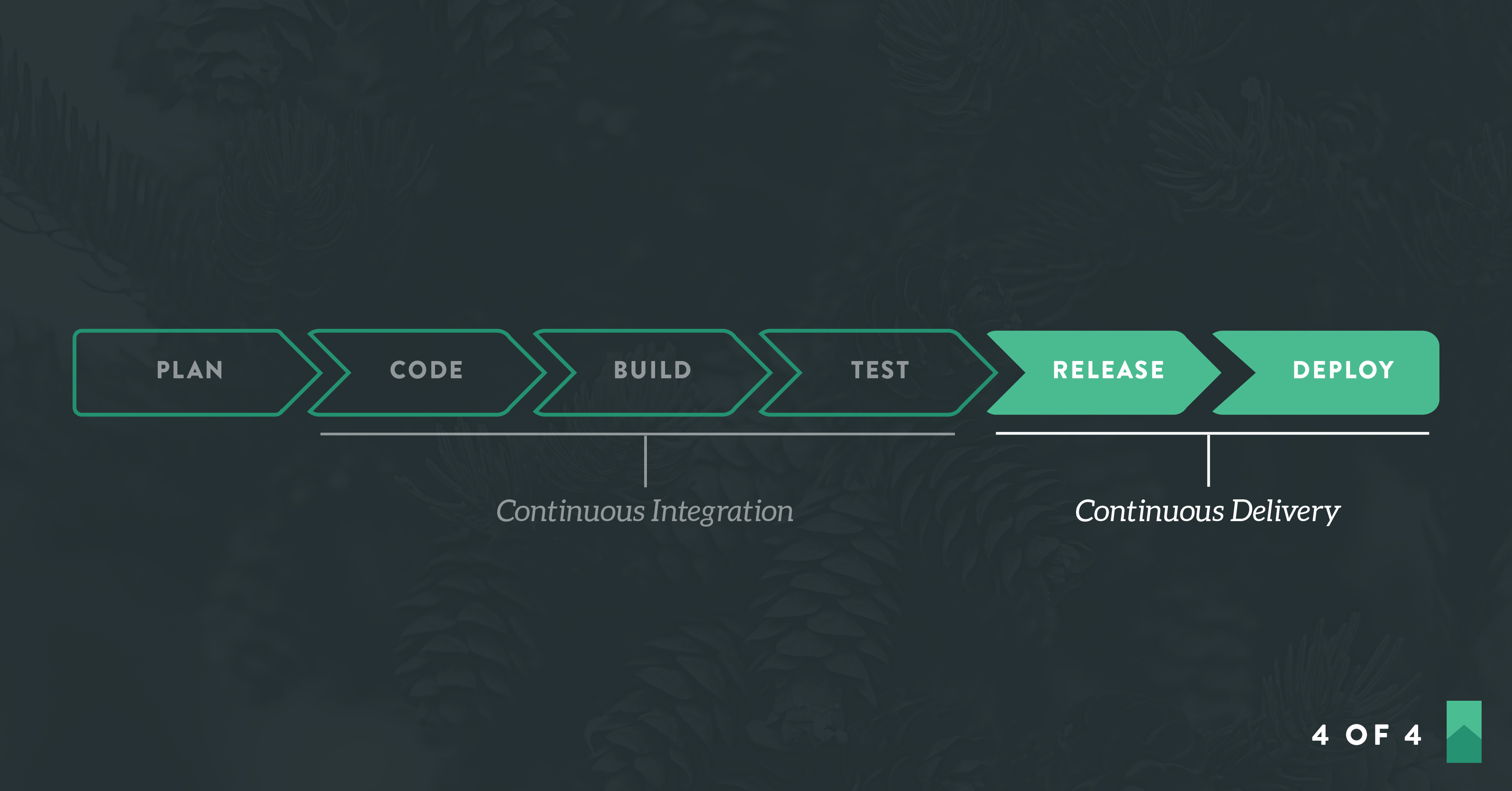
Now it’s time to complete the rest of the delivery pipeline: Continuous integration, static code analysis, and automated deployment. We did the application development work in Part 3. From here on out, it’s all configuration work. You became a programmer in Part 3. Now you’ll become an infrastructure engineer. (Well, sort of. Don’t get a big head.)
Step 8: Configure Continuous Integration
There are two things to do to get continuous integration working with your microservice. First, tell Travis that you want to connect your Github repository. You do this by flipping a switch on a Travis web page that looks like this:
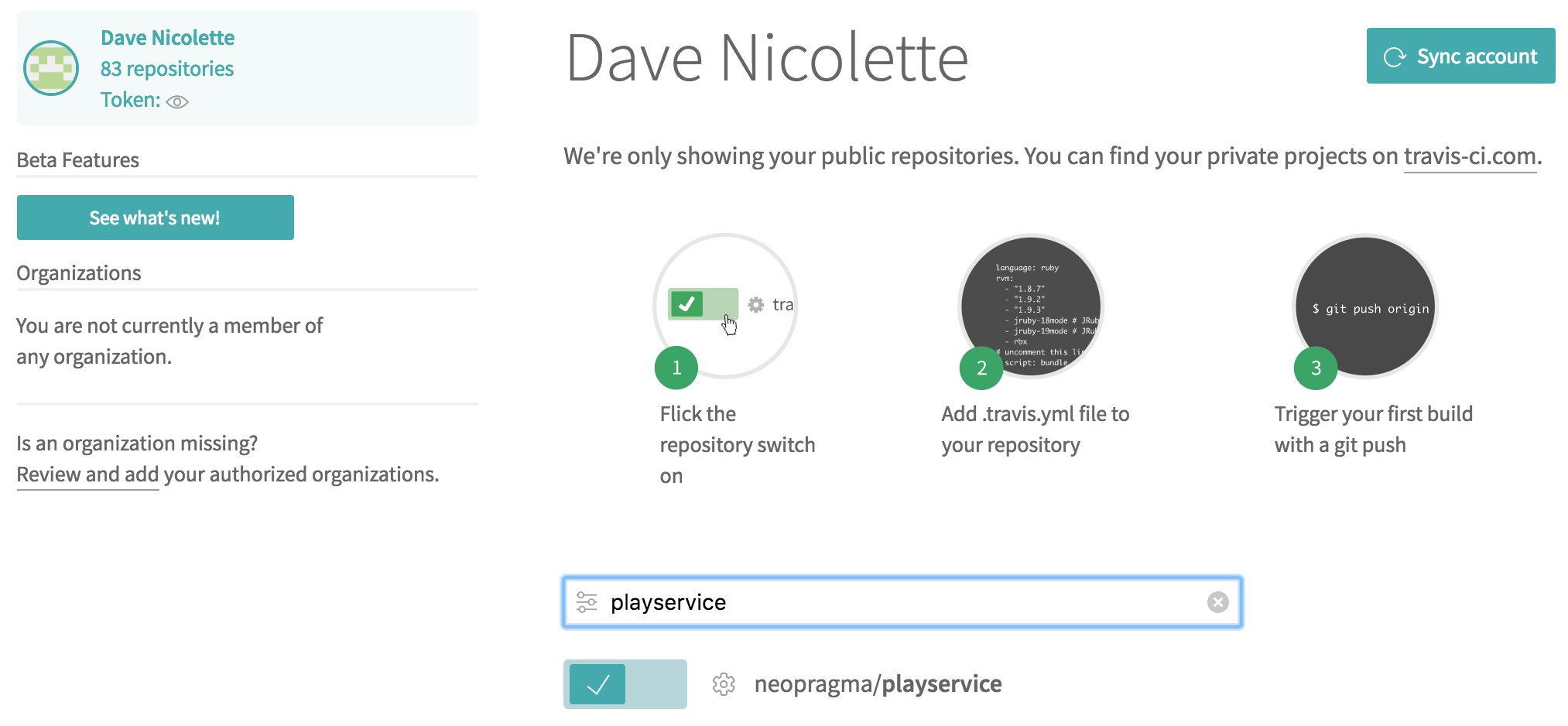
Next, add a configuration file to your Github project. In the project root directory, create a file named .travis.yml (yes, the name starts with a dot). Put the following data in the file:
notifications:
email:
recipients:
- youremail@something.com
on_success: change
on_failure: change
language: ruby
rvm:
- 2.3.1
branches:
only: master
install:
- bundle install
script:
- export PLAY_URL=http://0.0.0.0:4567
- rackup -P rackup.pid -p 4567 -o 0.0.0.0 &
- rake integration
- kill `cat rackup.pid`
Be sure to put your actual email address under recipients, rather than “youremail@something.com”.
==> Commit! <==
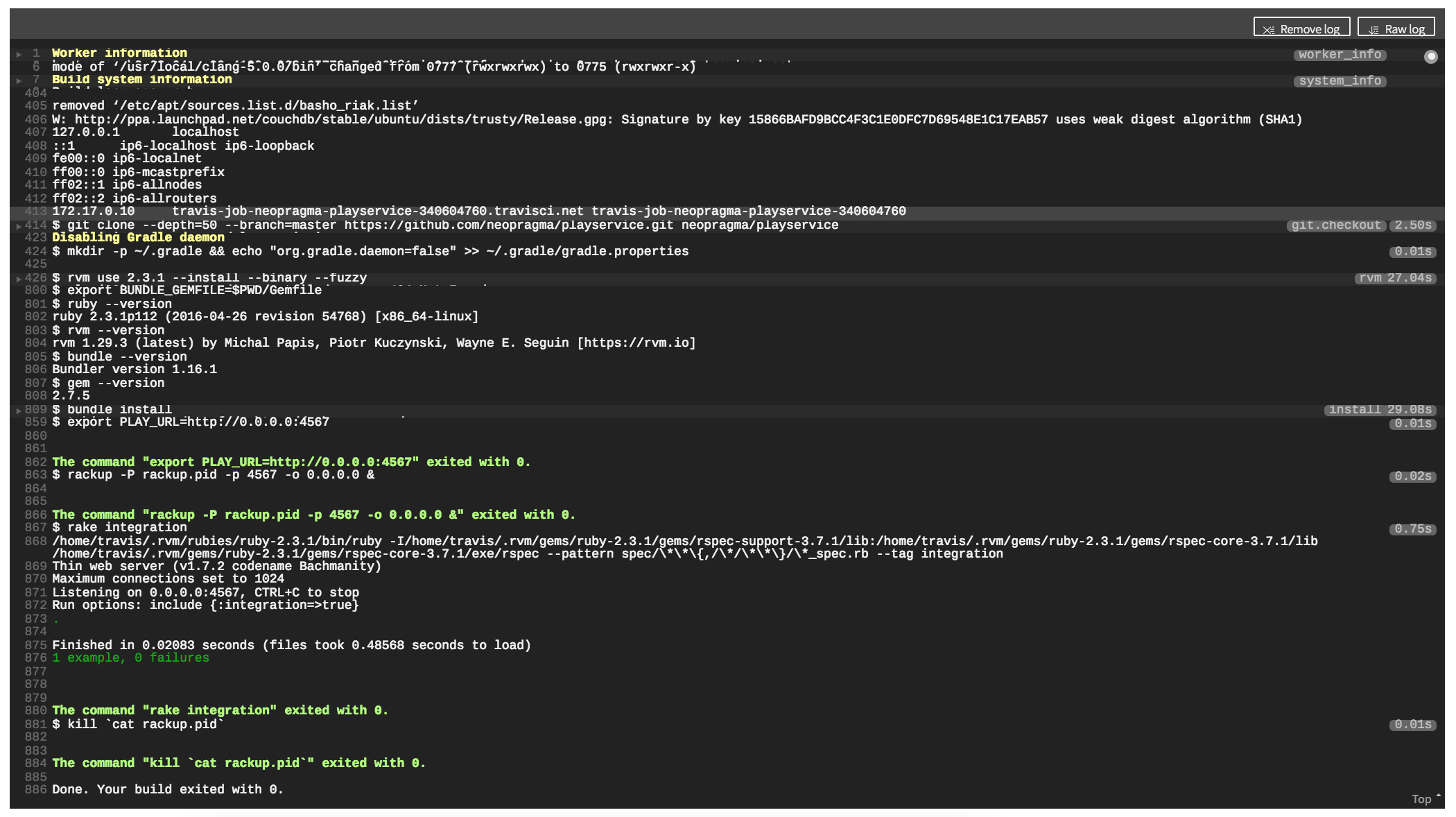
Once this is set up, each push to Github will initiate a build and test run on Travis. Here’s an excerpt of typical output from this, displayed on the Travis website.
Step 9: Configure Static Code Analysis
Now let’s add support for running static code analysis and test coverage analysis with CodeClimate. Sign into CodeClimate using the free (Open Source) account you created. Follow the steps to connect your microservice Github project to CodeClimate (see Adding Your First Repo. It will automatically analyze your project and take you to a report page.
That’s nice, but what you really want is to include the static code analysis and code coverage in your seamless, automated CI/CD pipeline. (This bit is considered part of CI rather than CD.) CodeClimate gives you some information about connecting their service with the continuous integration service of your choice (see Adding Travis-CI Test Coverage).
The key is the .travis.yml file you created to tie Travis-CI into your pipeline. Once you have connected your Github repo with CodeClimate, you can add some specifications to the .travis.yml file to cause Travis-CI to pull in CodeClimate static code analysis and reporting.
You’ll need the token that CodeClimate generates for you when you connect your Github repo. Documentation is here: Finding Your Test Coverage Token.
env:
global:
- CC_TEST_REPORTER_ID=your-test-coverage-token-goes-here
email:
recipients:
- davenicolette@gmail.com
on_success: change
on_failure: change
language: ruby
rvm:
- 2.3.1
before_script:
- curl -L https://codeclimate.com/downloads/test-reporter/test-reporter-latest-linux-amd64 > ./cc-test-reporter
- chmod +x ./cc-test-reporter
- ./cc-test-reporter before-build
branches:
only: master
install:
- bundle install
script:
- export PLAY_URL=http://0.0.0.0:4567
- rackup -P rackup.pid -p 4567 -o 0.0.0.0 &
- rake integration
- kill `cat rackup.pid`
after_script:
- ./cc-test-reporter after-build --exit-code $TRAVIS_TEST_RESULT
==> Commit! <==
The Travis-CI build will show the CodeClimate actions, but the actual report will not appear in the Travis-CI log output. To see the report, visit the CodeClimate website.
Step 10: Automated Deployment to Production
We’re almost home. There’s just one more piece to the pipeline: Automated deployment to production when the CI build and tests are successful. You set up a free account on Heroku, and that will be the production environment for your microservice.
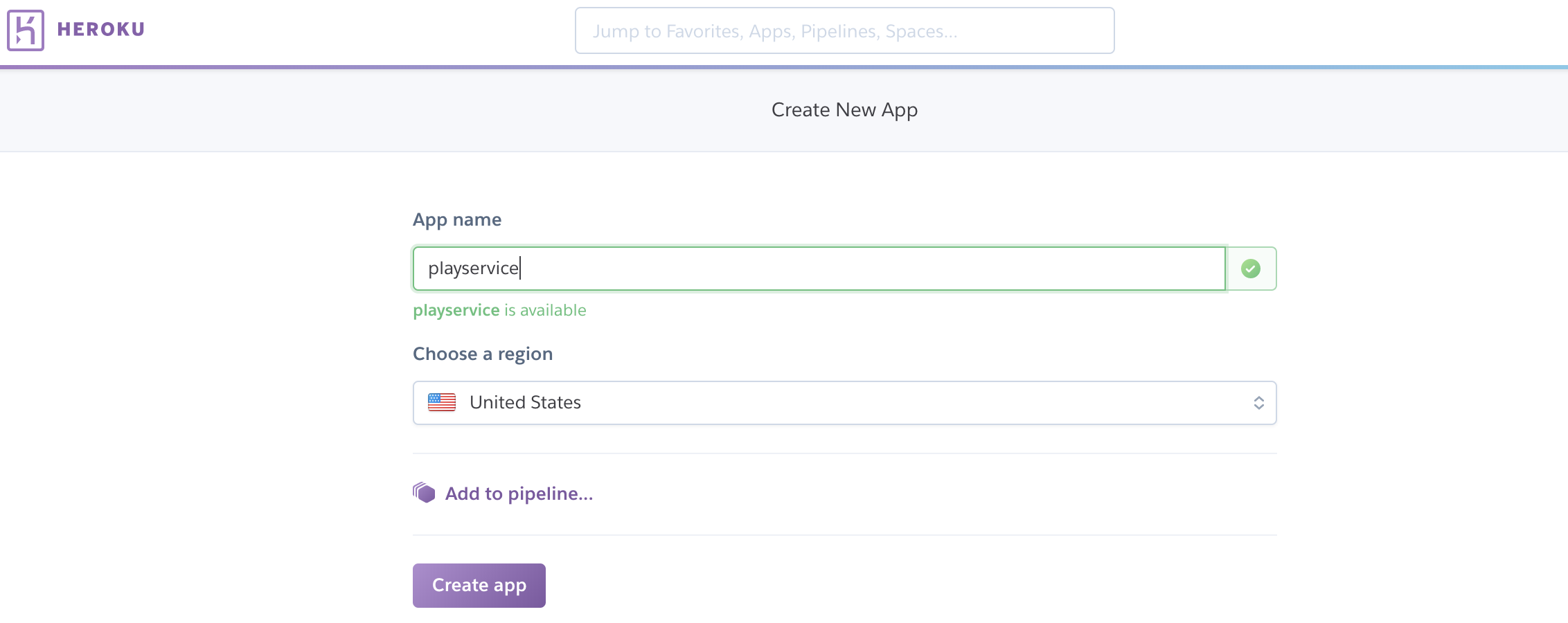
First, define your microservice to Heroku.
Download the Heroku command line app to your Code Anywhere container (see documentation):
wget -qO- https://cli-assets.heroku.com/install-ubuntu.sh | sh
Log into Heroku from the command line:
heroku login
When prompted, enter the userid and password you created when you signed up for Heroku.
Install the Travis-CI command line gem (see documentation):
gem install travis -v 1.8.8 --no-rdoc --no-ri
Use this command to get an API key, encrypt it, and add it to your .travis.yml file (documentation):
travis encrypt $(heroku auth:token) --add deploy.api_key
Automatic deployment is triggered by the continuous integration server, and we set it up by adding some specifications to the .travis.yml file. The details are documented on the Travis-CI site at Deployment to Heroku.
When you’ve added the deploy section to .travis.yml, it will look similar to this:
deploy:
provider: heroku
app: playservice
api_key:
secure: your secure API key, generated by the travis encrypt command
Create a file in the root directory of your project named Procfile containing this line:
web: rackup -p $PORT
That will be the command Heroku uses to start your web server. Don’t specify any ports or other arguments as you do in your development environment on Code Anywhere. Heroku will use the setting of the PORT environment variable, which it controls.
==> Commit! <==
And thus the moment of truth arrives. If all these various bits and pieces have been defined correctly, the push you just did to Github will trigger the entire pipeline, and you’ll be able to run your microservice in production (Heroku) by accessing a URL such as playservice.herokuapp.com/v1.0.0. You can watch the build on Travis-CI, and when it completes with success you can try your URL on Heroku.
Conclusion
If you’re coming from a non-technical role, and/or your technical skills are rusty, then I hope you’ve gained an appreciation for what it takes to do test-driven development and to set up a CI/CD pipeline for continuous delivery. This exercise has been a relatively simple example of those things, but still a pretty realistic one.
If you’re coming from a programming background, then I hope you’ve picked up some practical information about the “ops” side of devops. Similarly, if you’re coming from an infrastructure background, then I hope the section of the exercise that involved test-driven development was informative.
Part of the point of this exercise is to underscore the fact that CI and CD have moved quickly from somewhat arcane and “advanced” practices to commonplace, baseline expectations for software development and delivery. In addition, the cloud-based services and tooling available to support these things have matured very rapidly indeed. They are currently usable enough that a person need not be a deep expert in technical matters to build a simple application and set up automated testing, static code analysis, and deployment.
If you’re involved with software development and delivery in a technical role, the day is fast approaching when you won’t be able to get away with lacking these skills. If you’re still writing code without tests, think about it. If you’re still doing functional testing or “checking” manually, think about it. If you’re still configuring and provisioning servers manually, think about it.
Comment (1)
David
Hi Dave,
Highly appreciate your CI/CD building tutorial, but it would be nice to introduce security and privacy features on each of the four series. Thanks for sharing it.