The Urge to Strangle

Business agility means having the capability to “turn on a dime” at low cost and with low risk, to drive innovation, respond to market changes, and overcome the competition. In any enterprise that depends heavily on information systems, business agility is not possible without technical agility.
Companies that adopted information technology in the mid-20th century have built up large-scale operations around principles, methods, and tooling from an era when thorough up-front planning was an accepted good practice, and when “computer” meant “mainframe.” Their IT organizations are designed and built for that approach from the ground up. They face challenges in achieving agility that smaller or newer companies don’t.
The urgency only increases with time. Apart from positive reasons to enhance technical capability, the day-to-day operating costs of a large data center continue to rise, while the data center itself is not a revenue-generating resource (except indirectly, insofar as it supports other business operations). Unless your business is to rent data center facilities to customers, your data center is overhead. Leaders are keen to simplify their infrastructures, reduce overhead costs, and offload some of the work while increasing business agility.
When new capabilities come along, leaders are always hopeful they will help achieve these objectives. Today, it’s “cloud” and “serverless” and so forth. In the past, things like Service-Oriented Architecture (SOA), NoSQL databases, 4th-Generation Languages, CASE tools, and others have seemed promising. Large enterprises have tried all these things.
Once a technology becomes part of the environment it tends to stay there, even after the shine wears off. The new never fully replaces the old. The attempt to reduce the complexity of the technical environment results in adding yet another complication. Today’s new is added to the mix, and becomes part of tomorrow’s old.
The Parable of the Bridge and the Canoe
Most systems implemented in large IT organizations are point solutions implemented to solve local (departmental, business unit, or team) problems. There is rarely a clear connection between enterprise-level strategy and project-level decisions. One manager put it to me this way:
“We all know the company needs a bridge from the island to the mainland, but no manager wants to be the one to pay for a new bridge from their budget, and no individual manager really needs the full capability of an engineered bridge; we just need to carry a few things across. So, we keep building canoes as needed.”
My observation: This is a natural consequence of a “project” mentality as opposed to a “product” mentality. Mid-level IT managers compete to get their projects approved and funded. They are interested in their own issues, within their own area of responsibility. They know their solutions are of local scope, but they lack the power or influence to drive a comprehensive solution.
Besides that, individual performance incentives tend to discourage global thinking, and encourage managers to do the things that are likely to maximize their chances of a bonus; generally, short-term numbers with a focus on shepherding the allocated funds rather than maximizing return.
Each project is treated as independent of others, each receives a fixed budget allocation, and small requests stand a better chance of being approved than large ones. The “project” mentality all but guarantees managers will always build a canoe, and no one will volunteer to build the bridge.
Partial solutions strung together
Applications are selected or created in isolation to address local needs. They are not designed to interoperate. They may provide overlapping or redundant functionality. They are built with different programming languages on different platforms and use different data stores.
As people elsewhere in the organization learn about local solutions that provide partial support for their needs, they introduce various point-to-point interfaces and data feeds among these systems as a way to cobble together more-complete solutions.
An example comes to mind from a large financial institution. I was showing their development teams how to automate functional tests using Cucumber. During a workshop for one of the teams, I learned they did not write or maintain application code. Their main job was to take an Excel file produced by a particular business unit and manually enter data from the spreadsheet into a CICS application through an IBM 3270 terminal. This activity took between 40 and 60 hours per week.
As they were working through the hands-on exercises, their lead Business Analyst asked, “Can Cucumber read Excel files?” I replied that Cucumber was written in Ruby, and Ruby can do anything for which a “gem” (library) exists. There are gems to manipulate Excel files. “Can it access CICS screens?” Yes, there’s a gem that behaves like an IBM 3270 terminal. The team stopped doing the workshop exercise and immediately put together a crude version of a Ruby script to read the Excel file, connect to CICS, and populate the CICS application with the data. It saved them a lot of time.
As clever as the solution was, it didn’t address the root problem: The organization did not have a solution in place that satisfied the needs of that business unit. The workaround was off the IT department’s radar. If the desktop computer in the business area broke, the Excel file would be lost. If something happened to the Ruby script (which was not officially a production resource), the solution would be broken.
Once a solution exists, it is practically inevitable that someone in the organization will become dependent on it to do their work, even if unofficially and without support or general awareness of the dependency. In many cases, no one in the organization knows all the cross-system and cross-departmental dependencies or the potential impact of changing or removing any of the interfaces or data feeds.
Shadow IT and ad hoc solutions
Not all the unofficial solutions are produced and used within the IT department. Individuals throughout the company create manual work flows, sophisticated spreadsheet applications, and desktop database applications that depend on one or more production applications or data stores without informing the IT department. People sign up for “trial” or “free” versions of Internet-based services to help themselves get their work done. Business processes may become dependent on these resources.
Most of these ad hoc solutions begin life as a quick-and-dirty answer to a local need, and later become critical to business operations. It’s common for these local solutions to have hard dependencies on “real” systems in the form of data dumps or screen scrapes, or possibly manual processes that depend on certain information appearing on a report or screen.
Dependencies like these are very difficult to trace, as there’s no record of them; there was never a “project” to create them. Yet, if a data source or application were to disappear, it could break a local point solution that has quietly become mission-critical.
Unofficial IT’s risks and costs
The situation is common in large organizations that have been around a while. On the plus side, it demonstrates creativity, initiative, and a motivation to help the company succeed. But there are risks:
- additional cost due to redundant or overlapping functionality in disparate point solutions
- duplicate, inconsistent, incomplete data used to inform business decisions
- inconsistent customer experience, such as being asked for the same information on multiple forms or in the midst of multiple procedures
- staff onboarding and mobility between teams is problematic, as each team uses unique, one-off software and procedures
- unofficial solutions have no budget or personnel for technical support, and no proper access to IT departmental support
- unofficial resources such as servers and database systems may not be available, performant, up to date, recoverable, scalable, or able to be integrated with enterprise systems
- unofficial data stores are not included in standard system backups
- unofficial solutions are not included in the disaster recovery procedure
- unofficial solutions may not have been vetted for security risks, regulatory compliance, or legal issues
People know these risks exist even if they lack specific information about how many unofficial solutions are in use, or where they are located. It makes them hesitant to make significant changes in the technical environment. Without change, there can be no improvement. Thus: No improvement.
The initiative and creativity of the people involved are to be praised, but the organization is dependent on high-risk workarounds rather than properly designed and supported solutions. Who knows how many of these are in use? How many hardware failures, power outages, fires, hackers, unintentional violations of regulations, or disgruntled employees would it take to scuttle the whole company?
Best of breed != suited to purpose
Another source of complication is a sort of “best-of-breed” mania that sweeps through corporate IT organizations periodically. I call it the Blackbird Effect. The concept is this: The SR-71 Blackbird is a very fast, very high-flying aircraft. You could call it a “best of breed” aircraft. But if you tried to use one as a crop-duster, you’d achieve very poor results. It isn’t suited to that purpose.


IT leadership may get it into their collective head that the company needs best of breed solutions in every category, regardless of the company’s business model or strategic plan. They reckon that no matter what “the business” asks for, they will be able to provide it in spades if they have best of breed products in place for every conceivable purpose.
Generally, the organization ends up with problems like these:
- Unused product – the organization has no use case for the product
- Underused product – the organization cannot load a high-volume product sufficiently to make proper use of it
- Misunderstood product – the product does not work the way the organization thinks it does
An example of the first case could be an organization that purchases an expensive workflow automation product, but has no need for workflow automation solutions. This sort of thing happens far more often than you might imagine. Many companies are paying fees for products they don’t use. The manager who approved the purchase may put political pressure on development teams to include the product in the solutions they build, and some teams may attempt to do so.
For example, in one organization where I worked a team was pressured to make use of a certain business process engineering package when the solution really didn’t require that type of product. They wrote a user exit and routed all traffic around the actual product, to make it appear as if the product were being used in production, so the manager would not be punished for approving the purchase.
In another case, a vendor offered a very good integration server product that the client company, a mid-sized bank, could use effectively. The vendor also offered a package of other products as a bundle, including an international business-to-business trading platform that had emerged from the shipping industry. The bank operated in 6 US states only. They had no use for a product like that. Yet, they decided to subscribe to the full suite of products from that vendor, so they could claim to have “best of breed” solutions in house.
Many large organizations have high-volume products in production when they don’t have high-volume workloads. I’ve seen several cases when a high-capacity OLTP server was in place when there was no need for it. The general pattern here is that the organization has a misconception of what “high volume” means. They think they have high volume, but compared with, say, American Airlines or American Express, they really don’t.
A product that is engineered for truly high-volume workloads operates differently from a “typical” product of the same type; it doesn’t simply do “more” of what the lower-end products do. It will be ready to spring into action without delay as soon as it receives an event. That means it’s monitoring an event queue or otherwise polling for activity, and “spinning” internally to prevent components from being paged out of memory. Products like these also make direct use of specific features of hardware platforms and operating systems that must be tuned specifically to maximize throughput under load. When the product is fully loaded, it handles everything smoothly. When the product is under-loaded, it thrashes; it’s constantly trying to do something, because it’s designed to be busy at all times.
The SR-71 analogy applies here. An SR-71 is designed to “live” at high altitude and high speed for upwards of 12 hours at a time. Its body panels are fitted loosely and corrugated so that the high temperatures and pressures in flight will shape the fuselage and hold it together. The engines are meant to operate as ramjets most of the time, and reconfigure themselves into “normal” engines for takeoff and landing only. If you flew it at 50 ft and 75 miles per hour, like a crop-duster, it would not be able to stay in the air for very long, and it would leak toxic fuel all over your crops that could render the fields unusable for growing food.
Sometimes, organizations buy products that don’t fit the need because they don’t fully understand how the product works. A typical example is a Business Rules Engine. That type of product is based on an Inference Engine, which is a kind of software that determines the most efficient plan for evaluating a set of “rules” and then executes that plan. To do so, it first analyzes the input to determine the optimal order in which to evaluate the rules and builds a node structure that it then walks to come up with an answer. For this to be cost-effective, the execution time for the “execute” phase has to be significantly longer than the execution time for the “plan” phase. Otherwise, the execution time (and cost) will far exceed that of “normal” application code executing conditional logic.
In practice, that means you must have at least 1,000 rules (varies by product), and the rules must be independent of one another; that is, they can be evaluated in any order, so that the Inference Engine can determine the optimal sequence depending on each request. A rules engine can be very useful when a large number of rules go into making a decision, and especially when many different requests are possible, like when running “what if” scenarios in which the results of one query might inspire the creation of new requests.
In almost all cases that I’ve seen, the organization has around 15 to 20 rules and the rules are so designed that they must be executed sequentially, like an if/else structure in a program. Products do offer that mode of operation, but it bypasses the Inference Engine and executes the rules as conditional logic. The Inference Engine is the piece you’re paying for. If you don’t make proper use of it, the result is “hidden” logic that most of the technical staff can’t access or understand, with no benefit from the unique capabilities of the product, as well as arbitrary architectural complexity in the solutions that use the product.
The More Things Change, the More They Stay the Same
The cost of maintaining and operating a massive hodge-podge of disparate solutions that were not designed to interoperate can become untenable. People are quick to try anything that promises to alleviate the problem.
A repeating pattern is evident over the long term in larger IT organizations. In my view, the primary cause of this pattern has been the prevailing “project” mentality as opposed to a “product” mentality. If I may borrow an idea from the Lean school of thought, I might say there’s a tendency to optimize locally.
Here’s what has happened in corporate IT, starting in the 1970s.
First, point-to-point interfaces between disparate systems accumulate as people cobble together useful solutions from whatever systems they can find or quickly put together using office software suites and end-user computing tools. In recent years, Open Source solutions have been added to the mix.
Eventually, someone in the IT department manages to get approval to do a project to create an “adapter” that will enable different applications to talk to each other in a clean way.
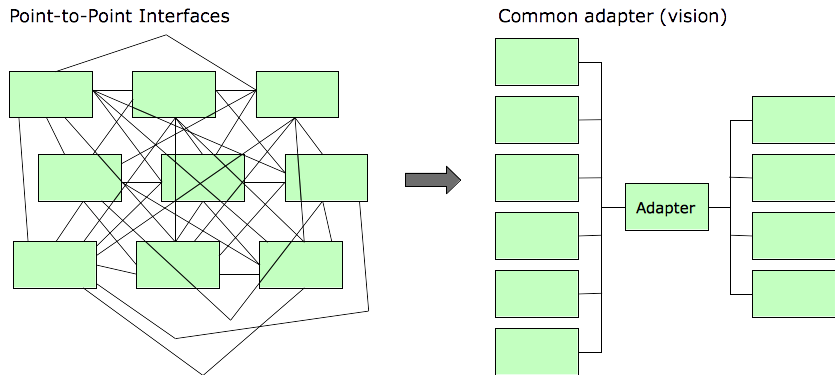
The difficulty of wrangling the point-to-point interfaces exceeds expectations, or at least exceeds the level of funding they were able to get approved, or perhaps tactical issues arise that force the organization to turn its attention elsewhere. For whatever reason, the conversion to the standard adapter is never completed.
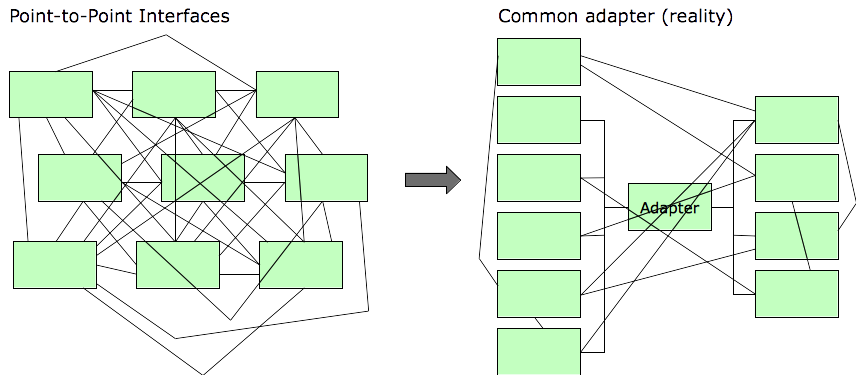
This happened a lot from the mid-1970s to the mid-1990s. By then, many large organizations were at a point where they were desperate to reduce costs and simplify the interactions among their systems. A new buzz-phrase was coined: Enterprise Application Integration (EAI).
EAI was supported either by home-grown solutions or by a category or products known as “integration servers.” Integration servers of the era had the capability to ingest record layout definitions, for instance mainframe COBOL copybooks or Assembly DSECTS, and provided a graphical interface people could use to draw lines between the corresponding data elements in two applications. They could also orchestrate work flows involving multiple systems.
The integration server could then pass data between the systems, converting it as needed, to provide seamless interoperation of applications. In this way, a COBOL application could be made to interoperate (on some level) with a Java or .NET application, each system transferring data and initiating transactions and batch processes on the other system as part of an overarching work flow.
In truth, those products worked pretty well, as long as you kept your expectations in check. The hope was EAI would lead to something like this:
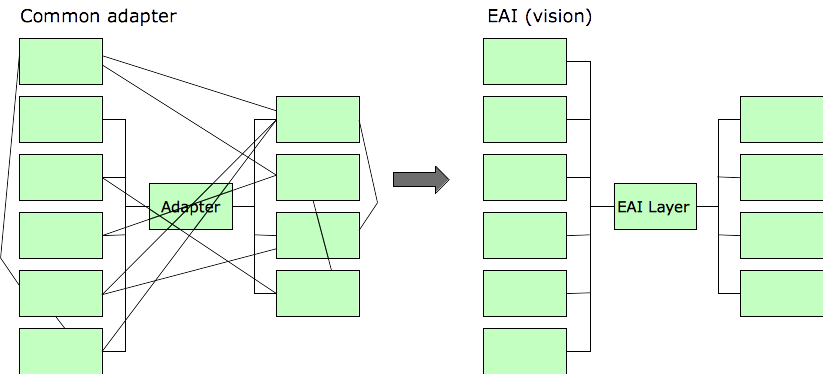
This is what really happened, for the familiar reasons:
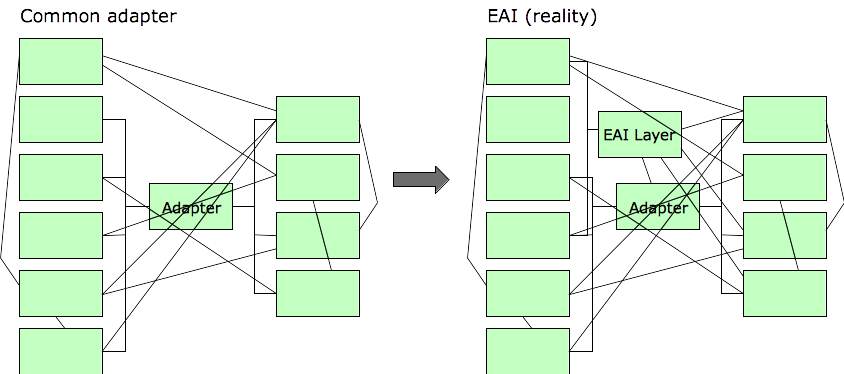
The next promising development was Service-Oriented Architecture (SOA). Fundamentally no different from EAI or any other sort of “adapter” layer, SOA promised to cut through the interface spaghetti. Instead of an integration server, SOA solutions had something called an Enterprise Service Bus (ESB). It was basically the same thing as an integration server, only shinier.
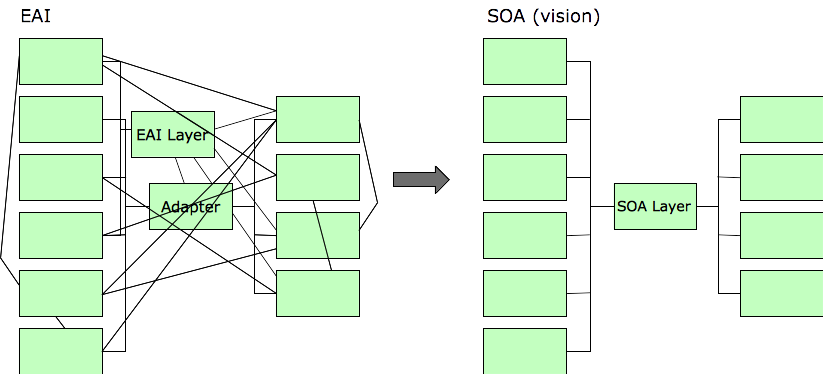
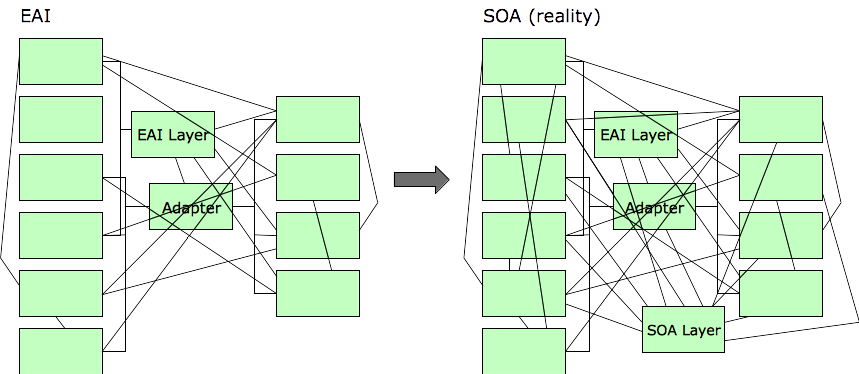
Here’s how that worked out. I think it worked out this way because the underlying “project” mentality was still in effect. As the old saying goes, repeating the same actions and expecting different results is a definition of insanity.
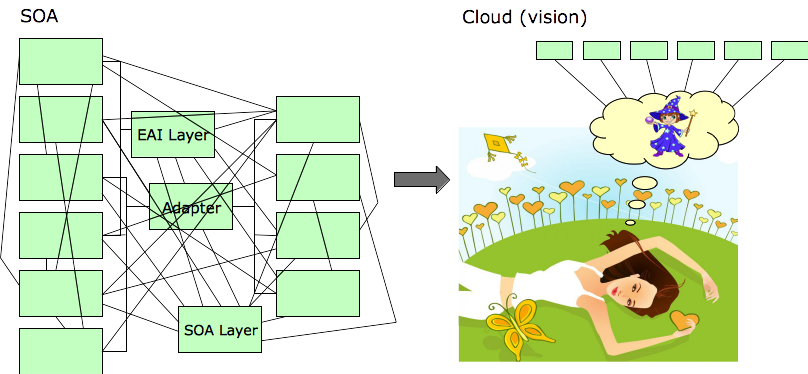
Today, people are very interested in taking advantage of the promise of “cloud” services. With complexity and cost higher than ever before, people have high hopes that “cloud” will solve their problems. Here’s a highly detailed technical diagram of how cloud services answer the challenges of enterprise IT operations.
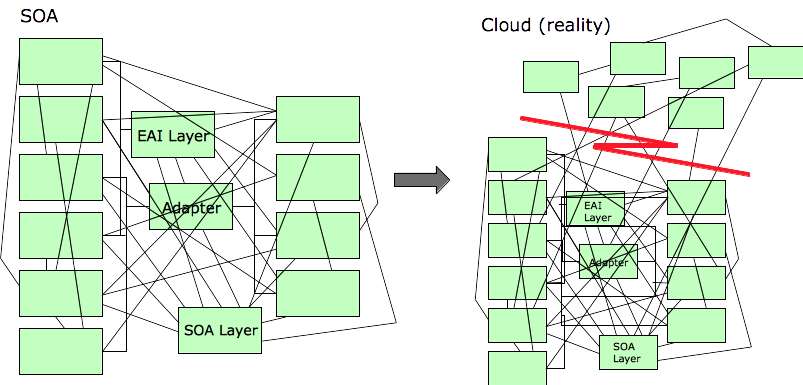
Except in the simplest of cases, people are experiencing this result:
Success Stories
The historical pattern does little to dampen enthusiasm. Many are reporting fantastic results from their cloud migration efforts.

If you ignore the systems that couldn’t be migrated to the cloud, then the picture looks pretty sunny. Well, provided you stand just here, and you don’t open any doors, and you don’t lean against the structure, and it isn’t too windy, and you don’t look behind the curtain.
Microservices? Well, that’s in plan for a future release. For now, just getting the monolithic applications into the cloud environment is a great step forward.
RESTful? Well, what does that even mean, anyhow, right? Heh, heh. It’s just a nerdy buzzword.
Serverless? Absolutely! We don’t run those servers anymore. The applications are in the cloud now.
Enter the Strangler
We’ve all heard about the Strangler Pattern. It’s a compelling idea: Introduce a layer of abstraction between system components, and then gradually replace the components one by one until the whole legacy system has been replaced.
It’s frequently recommended as a practical approach to migrating solutions to the cloud and restructuring them into a suite of microservices.
The idea can work quite well. Paul Hammant published an excellent write-up about practical applications of the Strangler Pattern and key success factors. The article also contains several case studies describing cases when the Strangler Pattern was applied to good effect.
For those working in large-scale, long-established enterprise IT environments with significant legacy technologies in place, Paul’s article offers a warning, probably unintentional, about the feasibility of the Strangler Pattern: The scope of the successful conversions was small, and the durations of the projects were long.
It would be prudent to let those two points sink in. Consider the scope of the case studies from his article, and compare them with typical enterprise-scale IT environments:
- Airline Booking. Legacy: C++, NSAPI. Replacement: Java, Spring. Scope: Single webapp. Duration: About 3 years, about 100 people in all contributed to the work at various times.
- Trading Company Blotter. Legacy: PowerBuilder, Sybase. Replacement: Java Swing with Dynamic Data Exchange to Excel spreadsheet. Duration: Not specified. Team: 1 XP team.
- Rail Booking App. Legacy: VisualBasic 6. Replacement: ASP.NET. Duration: About 2 years. Team: 1 XP team.
- Personal Management Portal. Legacy: Mixed Java web technologies. Replacement: JRuby on Rails, new functionality added during the strangulation process. Duration: About 2.5 years. Team: 1 XP team.
- Supermarket Planning App. Legacy: Java Swing + database. Replacement: Ruby on Rails + Java microservices. Duration: Multi-year plan (incomplete as of publication date). Team: Not specified.
- Magazine Web Portal: Legacy: Oracle Endeca. Replacement: Java + JavaScript. Duration: One year. Team: Not specified.
I’m not suggesting you should avoid the Strangler Pattern. I’m just saying you should be cognizant of the scope and complexity of the environment you’re dealing with. Notice the durations of these projects, even given the relatively small scope compared with a major enterprise-scale remediation.
Remember the history of similar efforts in the past: SOA initiatives often limped along for 5-6 years before being abandoned. The Strangler Pattern has some things in common with introducing SOA. In particular, both are based on the general approach of introducing a layer of abstraction behind which we can switch out components with no impact to users.
Both deliver good value, but not in a way that is immediately apparent to customers or to senior management. The initiatives have to be sold and re-sold to management over their course. The longer that course, the greater the likelihood the initiative will be canceled before everything has been converted, leaving us with a solution split between old and new components.
The projects Paul describes that had the best results were characterized by the following key success factors, which stand in contrast with the realities we typically face in large-scale enterprise IT environments:
- The technologies involved were amenable to the approach; the legacy technologies were not as problematic to address as large-scale enterprise IT systems (e.g., a single VisualBasic 6 app, or a single PowerBuilder app).
- The teams used robust development practices such as trunk-based development, frequent commits of small changes, frequent small releases, test-driven development, and incremental refactoring. These practices are rarely used in large corporate IT shops and are largely unknown to technical staff in those organizations. The particular practices I just mentioned are all routine with newer technology stacks, and all difficult to apply in a mainframe environment.
- The initiatives enjoyed consistent and capable management support; they were not canceled or dropped in priority due to emerging tactical issues along the way. In large IT shops, mid-level management turnover and top-down changes in strategy occur more frequently than a 2-3 year time frame; lengthy initiatives are likely to be canceled mid-stream, often for no reason except the initiative wasn’t the new manager’s idea.
- The teams comprised developers who were at the top of their field. Many of them were ThoughtWorkers or Thoughtworks-trained. This is uncommon in large corporate IT shops. More commonly, a mainframe IT shop has a handful of senior-level architects, a handful of old-timers who know the systems well, and a horde of coders who were hired at the lowest compensation levels the company could negotiate. It isn’t realistic to form multiple teams who possess the skills to take on a challenge like strangling off an old system. This factor alone will extend the timelines for any such initiatives.
- The components that had to be separated behind a proxy were not intimately tangled up with assorted impenetrable back-end systems, such that there is no single place to interpose a proxy that will catch all the accesses to the system-under-strangulation, as we often find in long-established mainframe environments. In particular, there was no batch processing. All client traffic could be intercepted by a proxy located at a single point in the network. That is not feasible in a mainframe environment in which hundreds or thousands of batch programs access the old system directly.
Lifting the Fog
When organizations attempt to introduce an abstraction layer to manage the various interfaces between applications, they usually assume everything that is currently in production is necessary. That can make any such initiative daunting. There are thousands of applications and packages in the environment, interrelated in complicated and poorly-understood ways.
But what if we don’t need to modernize everything? What if we only need to be concerned with a subset of current solutions? Remember the overlapping and redundant unofficial point solutions scattered throughout the organization? Remember the unused or underutilized Blackbirds in production?
Maybe a logical first step is to take stock and determine which resources are necessary and which are not. Then, we’ll have a firmer understanding of what we have and how it serves the enterprise, as well as fewer elements to deal with and less complexity generally.
Okay, fine, but how?
What do you do when your home is cluttered? The standard advice is to review everything you have and sort it into four piles:
- keep
- donate
- recycle
- discard
The principles are simple: Keep things you need, donate things someone else might need, and discard or recycle the rest. You can use the same strategy to organize your IT assets before diving into a time-consuming and expensive strangulation initiative.
In the context of an enterprise IT shop, you’ll get some special bonus gifts when you review all your assets:
- identify connections between applications
- identify redundant or overlapping applications
- discover how data really flows through the organization
- discover ad hoc or “shadow IT” solutions that must not be overlooked or ignored
How do we know what to keep, donate, or discard? When we Google “de-cluttering” or “organizing,” we find lots of advice about household items. Keep your family photos. Donate old computers. Recycle old paper and glass. Discard old broken things. But we don’t have any family photos in our enterprise IT shop.
No worries. Neil Nickolaisen’s Purpose Alignment Model can help. Here’s a standard consultant’s quadrant diagram (you can never have too many of those, you know):
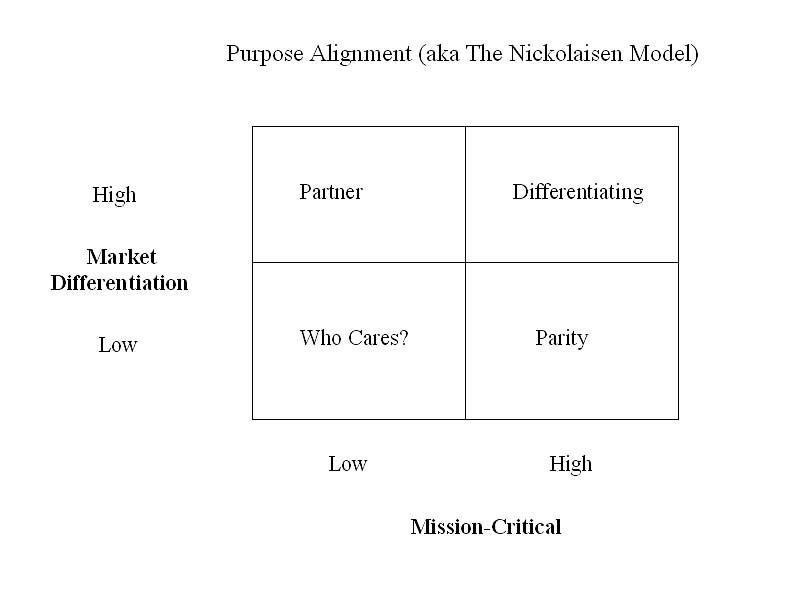
[1] High Market Differentiation and Mission Critical? Keep it. Not only that: Nurture it. This is the stuff that sets your company apart from the competition. Focus here.
[2] High Market Differentiation and not Mission Critical? Donate it. Find a partner; make a deal; get it off your plate. You’ll free up resources and people to focus on the High Market Differentiation and Mission Critical stuff.
[3] Low Market Differentition and Mission Critical? Recycle it. It’s probably a commodity service. You don’t need a partner, but you might be able to find a supplier or provider. There’s a difference.
[4] Low Market Differentiation and not Mission Critical? Discard it. Maybe it was valuable at some point in the past, but it isn’t anymore. It’s dead weight.
Not clear? Okay. Let’s say we’re a mortgage lender. We sort our activities into the four quadrants. We see that we really shine at loan origination. That’s quadrant [1] for us: Differentiating. We want to concentrate our energy on that.
Loan servicing doesn’t provide much revenue for us. So, we should keep loan origination and donate loan servicing. It’s important beyond the parity level, but not central to our business. It’s quadrant [2] for us: Partner. Make a deal with a loan servicing company (it’s in their quadrant [1]). The partner relationship (in contrast to the customer relationship) means we have assurances they will buy, as long as we do our part well; partners keep each other honest, which is good for everyone. Sell the paper to them after we fund the loans. Mutually beneficial.
We’re running our own payroll and benefits systems in-house. What the hell for? That’s quadrant [3] for us: Parity. We have to do it, but it isn’t market differentiating for us. We’re not in the payroll and benefits business, but other companies are. Sign up with one of them to provide the service for us (it’s in their quadrant [1]). It’s a commodity service, so we don’t need a partner relationship. In fact, we want the flexibility to switch suppliers if the need arises. So, we want a supplier-customer relationship here.
We complain about how hard it is to find good technical staff, and here we are paying half of our people to support commodity back-office systems instead of focusing on our market differentiators. Facepalm!
In the course of reviewing our hypothetical IT assets, say we discovered there are five different “systems of record” containing customer information. Unfortunately, that’s realistic. If that isn’t quadrant [4], then we’re on the wrong bus. It’s a Who cares? thing. Consolidate the systems. Dump four of them, or dump all five and replace them with something that serves the need more effectively.
More Than Meets the Eye
Pretty simple, eh? Just list out the systems in production and drop them into the quadrants one by one. Sure. But if it’s that easy, why haven’t we done it already? Maybe there’s more to it.
The Who cares? quadrant can be tricky in organizations that have some years on them. Systems that were mission-critical when first implemented decades ago may have been replaced by newer solutions, but remained in place as the official systems of record for the data on which the new systems depend. They feed mission critical systems, but they don’t perform mission critical functions themselves. This is a common pattern.
If the various systems of record were rationalized and redundant functionality consolidated, we may well find some systems that appeared to be in the Differentiating quandrant are no longer necessary at all; the true differentiating systems now have their own data stores, separate from the original (now obsolete) solution.
Consider an application that was implemented in, say, 1984 to perform credit risk analysis. It ingests external data feeds from other companies, combines that information with internal company data, runs analyses, and generates reports. It was superceded by a newer system in 1996.
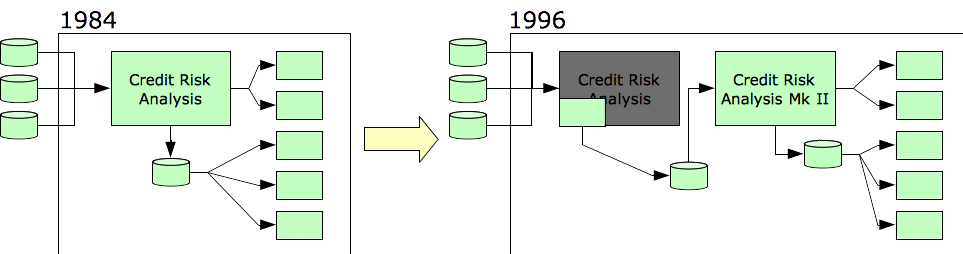
To implement the new system with minimal disruption to the business, the old system continued to function as the input point for the external data feeds, but it no longer processed the data. Now it passes the data along to the new credit risk analysis system.
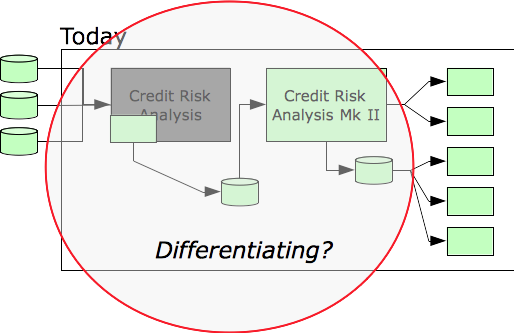
If we decide credit risk analysis belongs in the Differentiating quadrant, we will include the obsolete system as a mission critical resource because it is part of that process. But it isn’t really necessary. To prepare the organization for improvement, a preliminary step is to eliminate that system and simplify that process.
As a first step, we introduce an Extract-Transform-Load (ETL) product to help us isolate the original credit risk system.
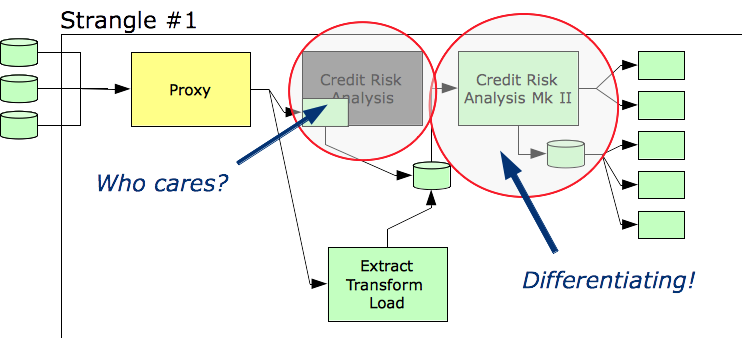
At this point, it’s a little clearer which assets belong in the Differentiating quadrant and which do not. Clearly, the scope of our strangulation effort will be smaller than it originally appeared.
The next step can be to shift the data feeds into the cloud, as well.
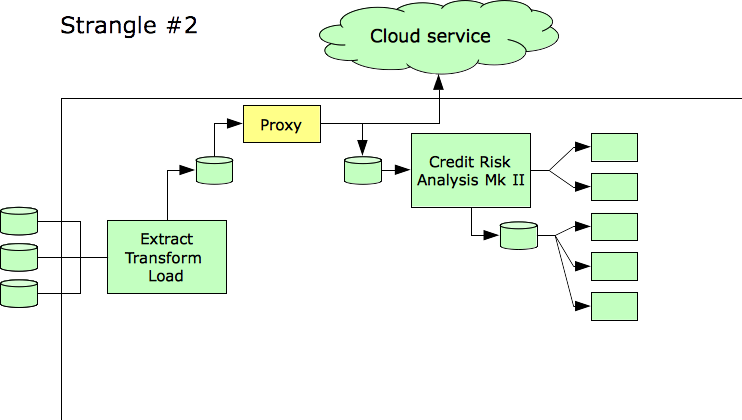
Ultimately we have achieved substantial simplification as well as shifted the day-to-day burden of operations to a company that specializes in operations. That company also handles network security and information security more effectively than we ever could, as those things are not our business focus.
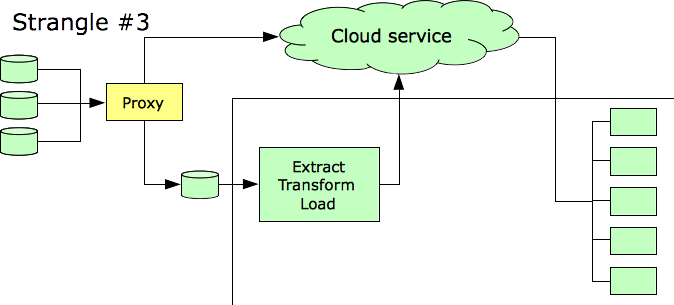
No solution is ever permanent. We’re left with an arrangement that is easier to modify than the original infrastructure. We’ve arrived there without interrupting customer service.
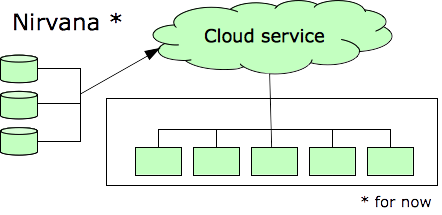
The case studies mentioned in Paul’s article were all multi-year initiatives. In our case, we still need several years to achieve our goal. The difference is that by carving out discrete steps, we know we’ll be in a better position than before even if the overall initiative has to be stopped before the planned end state. Whatever we spend will not be wasted.
Conclusion
The Strangler Pattern is straightforward to apply to simple cases, such as replacing a PowerBuilder or VisualBasic 6 solution with a Web-based or Cloud-based alternative. In mature enterprise IT environments, things are much more complicated. Yet, the Strangler Pattern can play a role, in conjunction with other techniques, in modernizing and simplifying the technical infrastructure and helping to enable business agility.
•• Graphics Credits
The aircraft photos are public domain images from Wikipedia.
The “Cloud (vision)” collage uses images from http://halloween-clipart.clipartonline.net/halloween-magic-wizard and http://www.clipartsuggest.com/relax-clipart-how-to-handle-stress-clipart-MyzLdN-clipart/ as well as LibreOffice clipart and shapes.
The photo of the false-front house is from http://www.impactlab.net/2011/10/23/top-10-photos-of-the-week-201/.
Neil Nickolaisen’s Purpose Alignment Model diagram has appeared in numerous places over the years. This one comes from an InformIT article from August 20, 2009, entitled “Breaking the Project Management Triangle.”
Other graphics were produced by the author using LibreOffice Impress.